
AI Models for Generating Images from Text: How Diffusion Models Outpaced DALL-E
28 March, 2024
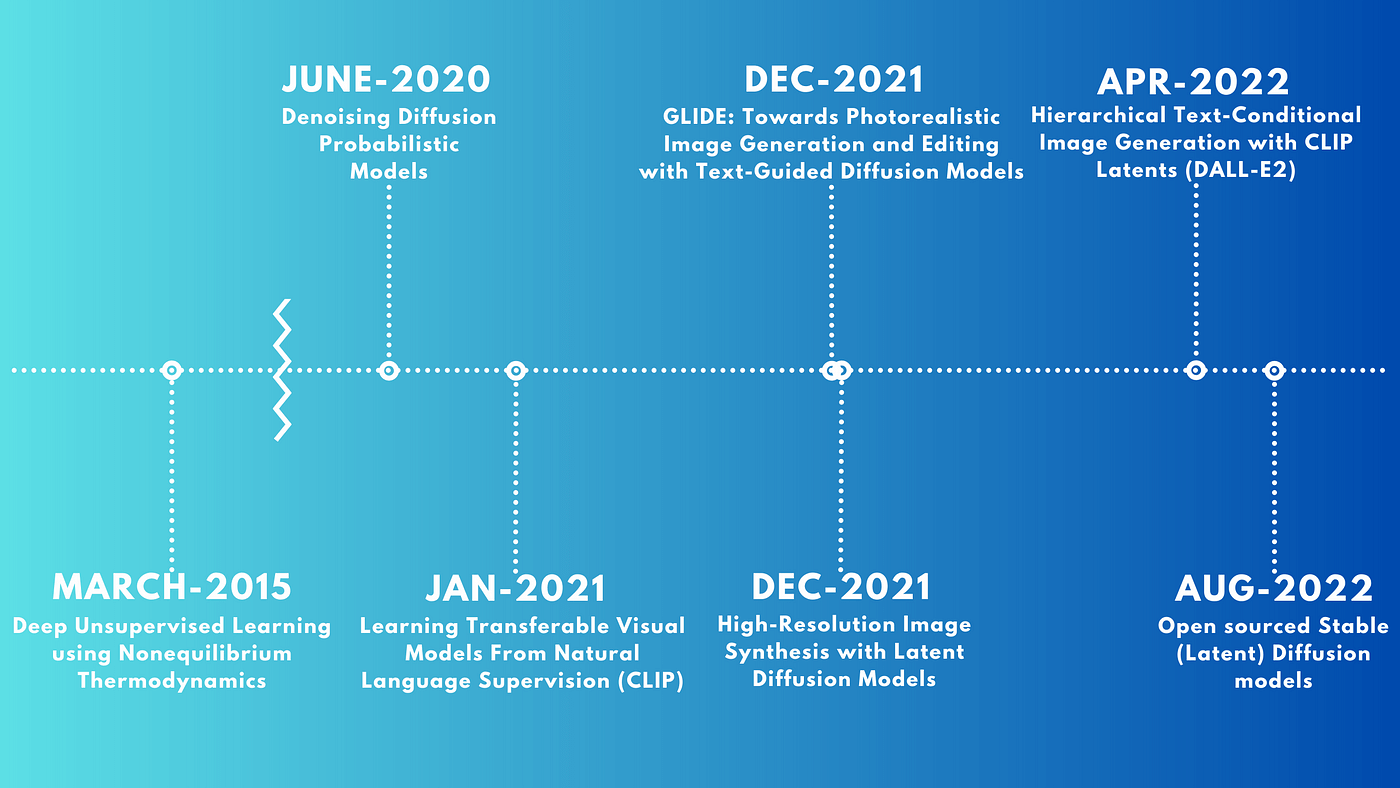
Generative modeling enthusiasts have been living a dream over the past year and a half. Recent months have witnessed exciting developments and research papers focused on text-to-image generation. Each new approach seems to outshine the previous one. Social media platforms are now flooded with stunning images created entirely by AI. Imagine a golden retriever eloquently answering tough questions on the campaign trail or a brain zooming to the moon aboard a rocketship.
In this post, we’ll delve into the recent history of solving the text-to-image challenge and explore the latest breakthroughs related to diffusion models. These models play a pivotal role in cutting-edge architectures.
DALL-E vs. Midjourney AI vs. Stable Diffusion
Generative AI models have an impressive ability: they can create lifelike and varied images based on written descriptions. Think of it as turning words into pictures! These models, like DALL-E, Midjourney AI, and Stable Diffusion, showcase remarkable creativity and adaptability. But how do these models actually function? And which one stands out? In this blog, we’ll delve into the workings of DALL-E, Midjourney AI, and Stable Diffusion, comparing their strengths and features.
What is DALL-E?
DALL-E is an artificial intelligence model developed by OpenAI. It made its debut earlier this year. It’s a variant of GPT-3, which is a powerful language model capable of generating text based on various prompts.
DALL-E’s Unique Skill: Text-to-Image Generation
Unlike GPT-3, DALL-E has an extraordinary ability: it can create images from text descriptions. Imagine typing a sentence like “an armchair in the shape of an avocado” or “a snail made of a harp.” DALL-E can turn these words into actual visual representations! Notably, it can even produce multiple images for a single prompt, showcasing its creativity and flexibility.
How DALL-E Works
- Neural Network Architecture: DALL-E employs a neural network architecture called Transformer.
- Text and Image Processing: It uses a single Transformer model that can handle both text and image tokens as inputs and outputs.
- VQ-VAE Technique: DALL-E also utilizes a technique called VQ-VAE to compress high-resolution images into discrete tokens. These tokens are then fed into the Transformer model.
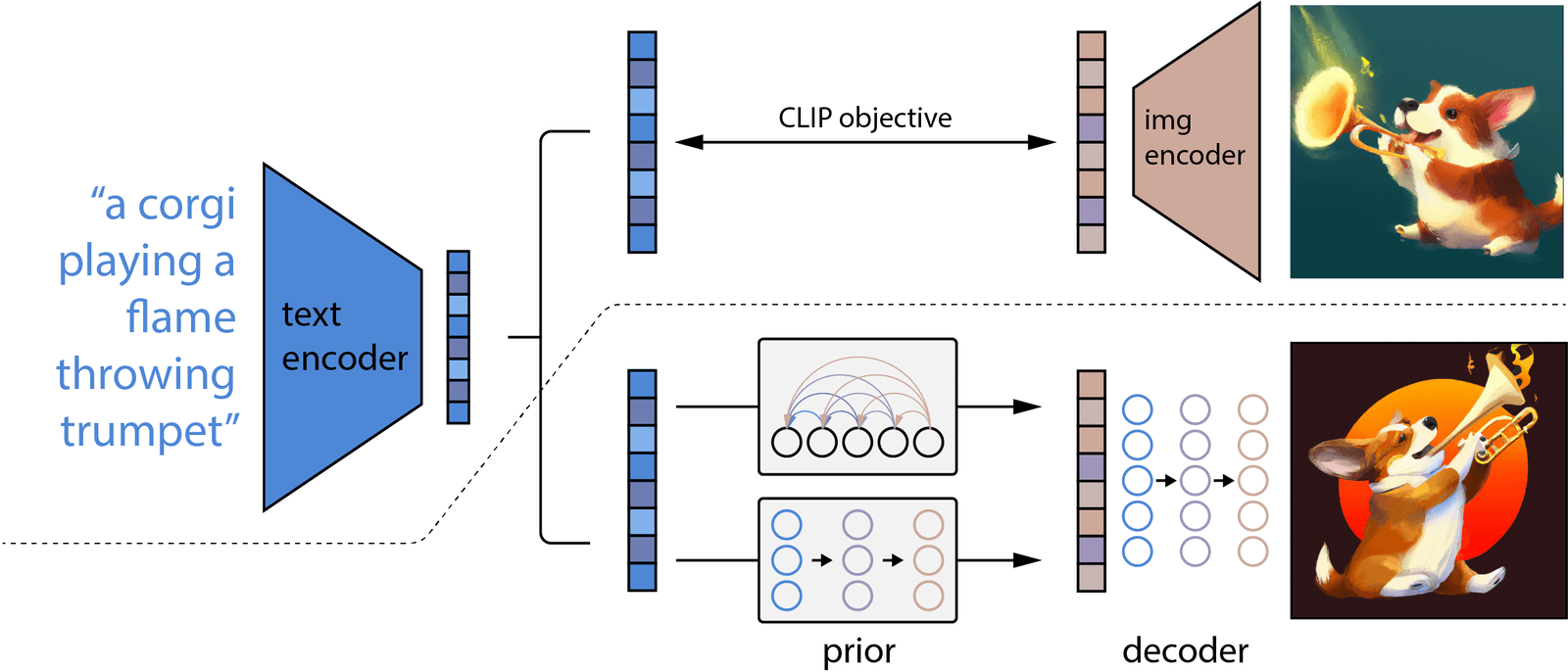
In 2021, researchers at OpenAI introduced a new AI system called DALL·E that showed the world what was possible when language and vision models merged. DALL-E stood for Direct Speech-to-Image and it allowed users to generate original images simply by describing them in text.
This was built upon recent advances in natural language processing, notably GPT-3 which demonstrated how large AI models could understand, generate and reason about human language at a new level. DALL-E took things a step further by incorporating computer vision capabilities. It was able to interpret text descriptions and render visual representations of what was described.
Under the hood, DALL-E used a two phase process. First, it compressed images into "tokens" much like words are broken down in language models. It then trained a large transformer model to understand the relationship between these visual tokens and words or phrases. By learning from hundreds of millions of text-image pairs online, DALL-E was able to grasp how language and images are interconnected.
When prompted with text, DALL-E could tap into this understanding to envision potential images and generate new visual creations that captured the imagined scene or object. This opened up new creative avenues for digital art and sparked fascination with what AI systems may be capable of in the future as language and perception continue advancing together.
Image Resolution and Complexity
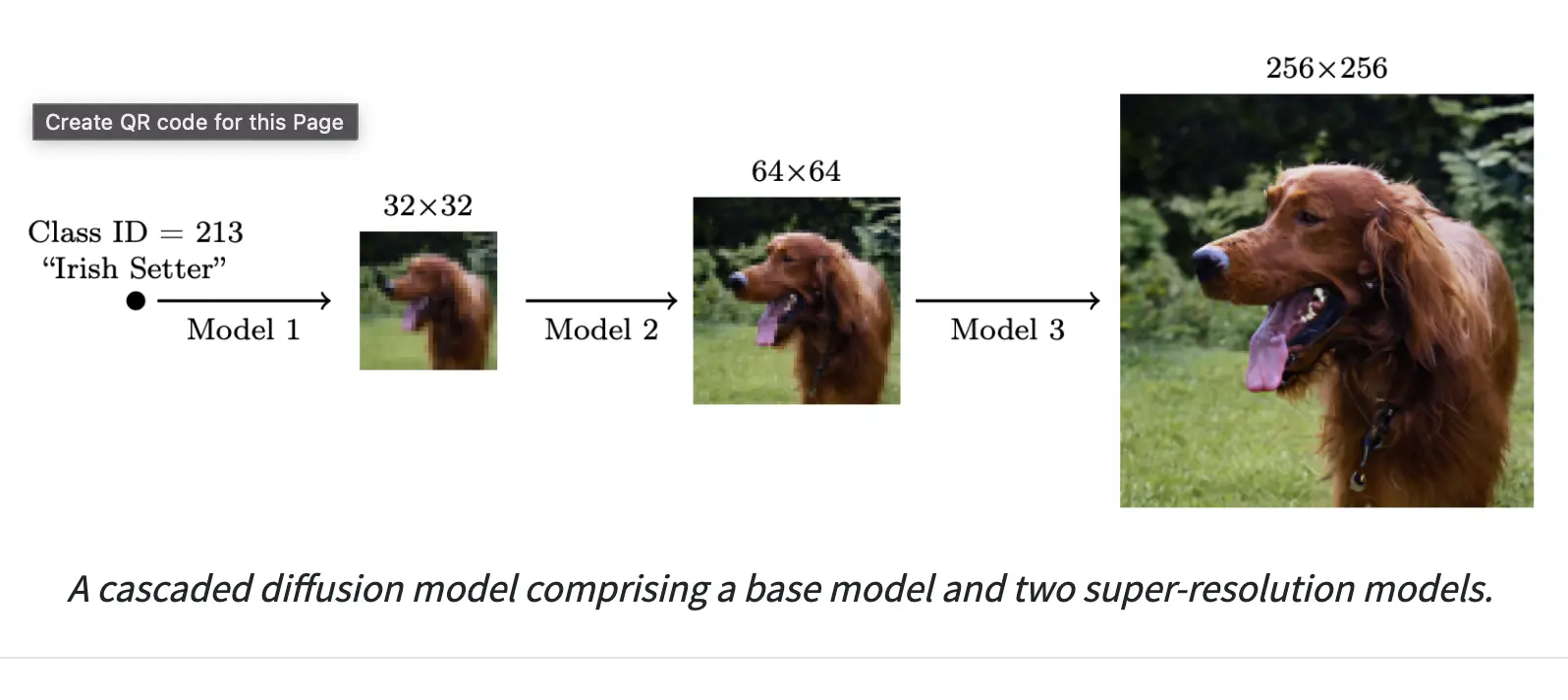
DALL-E generates images at a resolution of 64x64 pixels, which is relatively low compared to other image models. Despite this, it still produces impressive results, capturing the essence and details of the given text descriptions. It can handle complex and abstract concepts, such as “a painting of a capybara sitting in a field at sunrise” or “a diagram explaining how DALL-E works.”
What is Midjourney AI?
Midjourney AI is an AI model developed by an independent research lab called Midjourney Lab. Like DALL-E, it’s also a variant of GPT-3, but it takes a different approach to create images from text descriptions.

Guiding the Image Generation Process
CLIP: Midjourney AI leverages a technique called CLIP.
What’s CLIP?: Introduced by OpenAI, CLIP stands for Contrastive Language-Image Pre-training.
CLIP’s Abilities: It learns to associate text and images across various domains and tasks.
Image Tasks: CLIP can perform tasks like classification, captioning, and retrieval.
In essence, CLIP provided a solution for reliably pairing text with corresponding images. Its training approach was conceptually straightforward - encode many text-image pairs and learn their relationships. Specifically, the model took in paired examples harvested from online and trained contrastively to understand the correlation between visual and linguistic representations. This allowed using CLIP to score how accurately model’s image candidates captured the meaning of the input text, providing an effective evaluation method for the generative models.
How Midjourney AI Works
Feedback Mechanism: Midjourney AI uses CLIP as a feedback mechanism during image generation.
Starting Point: A random noise image which iteratively gets modified.
Goal: The aim is to make the image closely match the given text description, as evaluated by CLIP.
Style and Diversity: Midjourney AI also employs StyleGAN2 to inject style and diversity into the generated images.
Image Resolution and Artistic Output
Resolution: Midjourney AI can create images at a higher resolution of 256x256 pixels compared to DALL-E.
Realistic and Expressive: It excels at producing realistic and diverse images that capture the style and mood of the text descriptions. Examples include “a portrait of Frida Kahlo with flowers in her hair” or “a surreal landscape with floating islands.”
What is Stable Diffusion?
Stable Diffusion is an AI model developed by a startup called Stability AI. Their focus? Building and sharing cutting-edge natural language technologies.
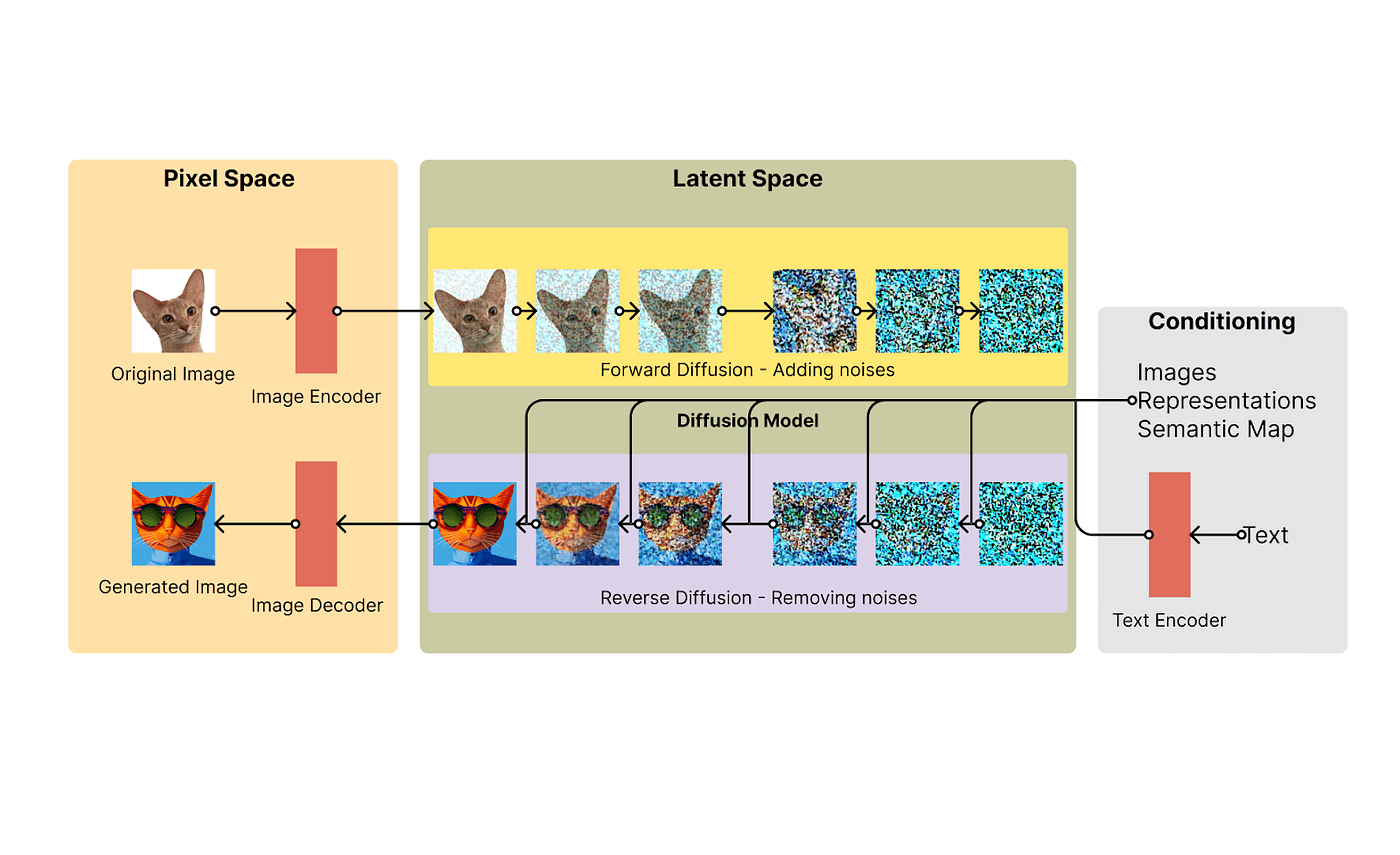
The Breakthroughs Behind Stable Diffusion
Diffusion Models: These are a class of generative models.
How They Work: Diffusion models reverse a process that gradually corrupts an image or text until it turns into pure noise.
High-Quality Samples: By reversing this process, they create high-quality samples from noise using learned denoising steps.
Performance: Diffusion models outperform other generative models like GANs and VAEs in terms of fidelity and diversity.
Stable Diffusion’s Approach
Training Data: Stable Diffusion trains on a large dataset of images and their corresponding text descriptions (sourced from DALL-E).
Text Encoding: It uses the same text encoder as DALL-E to convert text descriptions into latent vectors.
Conditioning: These vectors guide the diffusion model during image generation.
Annealed Sampling: Stable Diffusion employs a technique called annealed sampling to enhance image quality and diversity.
Image Resolution and Creativity
Resolution: Stable Diffusion can create images at a higher resolution of 256x256 pixels compared to DALL-E.
Diverse and Realistic: Leveraging diffusion models, it generates more diverse and realistic images. Examples include “a photo of a dog wearing sunglasses” or “a sketch of a dragon breathing fire.”
Diffusion Models: Understanding Stable Diffusion
Stable Diffusion belongs to a class of deep learning models known as diffusion models. These models are specifically designed to generate new data that resembles what they have encountered during training. In the case of Stable Diffusion, the data in focus are images. But why the name “diffusion model”? The answer lies in the mathematical resemblance to the natural process of diffusion observed in physics.
Imagine the movement of molecules from areas of high concentration to low concentration—this is diffusion. In the context of machine learning, diffusion models operate by reversing this process. They intentionally introduce random noise to existing data and then work backward to recover the original data distribution from the noisy samples. Essentially, diffusion models aim to undo the information loss caused by noise intervention, resulting in high-quality data generation.
Foundation for Understanding: The Role of Diffusion Models
Beyond their technical intricacies, diffusion models serve as a powerful mechanism for understanding and predicting the dispersion or movement of entities over time. Initially, the concept might appear abstract, but it underpins various phenomena. Whether it’s the subtle diffusion of fragrance within a room or the spread of rumors within a community, diffusion models find seamless application across different scenarios. By grasping the principles of diffusion, we gain insights into how information, patterns, and influences propagate—a fundamental understanding that transcends disciplines and enriches our comprehension of dynamic processes.
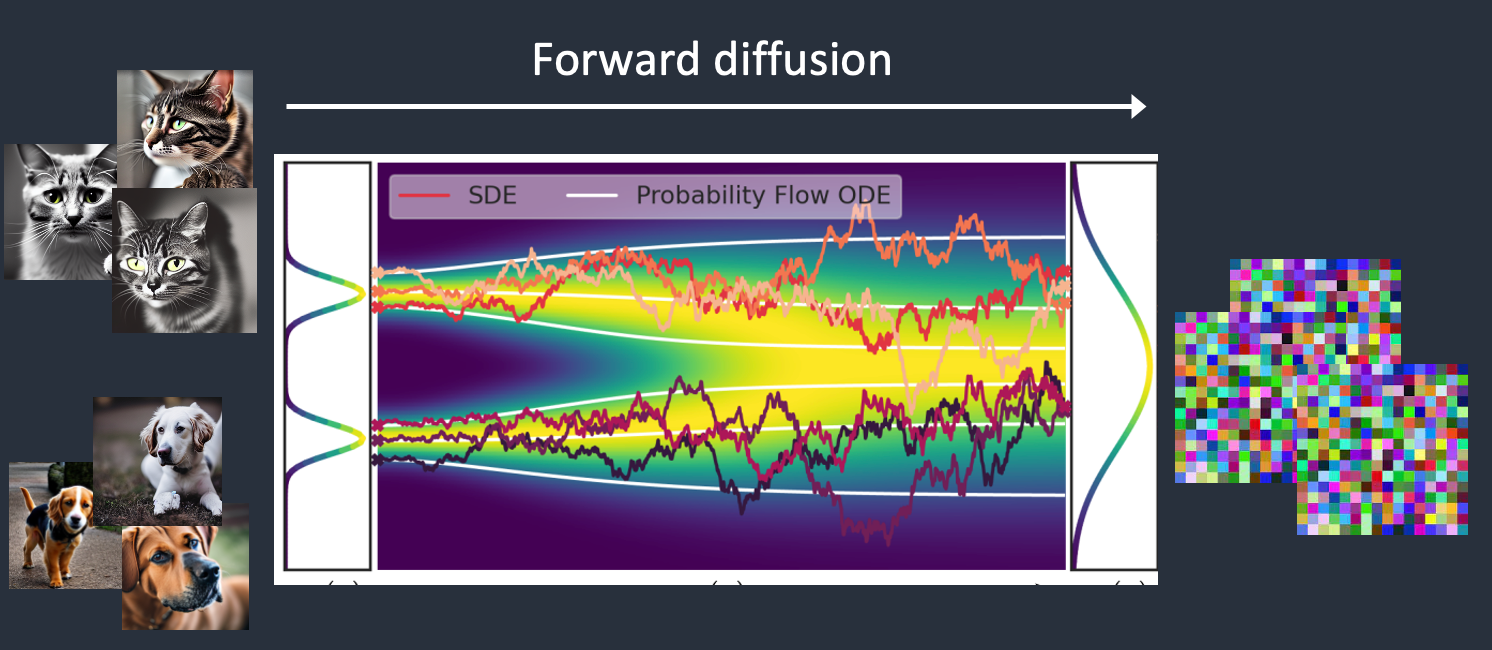
Forward Diffusion and Noise Introduction:
- The journey begins with a simple sample drawn from a basic distribution, often Gaussian. This initial seed represents minimal information.
- The magic lies in the subsequent steps: reversible, incremental modifications. At each stage, controlled complexity is introduced.
- Imagine it as adding layers of structured noise. Like a painter building up colors on a canvas, the model gradually enriches the data.
- The purpose? To capture intricate patterns and details inherent in the target distribution.
The Ultimate Goal
As the forward diffusion process unfolds, these humble beginnings evolve. They transform into samples that closely mimic the desired complex data distribution. Think of it as starting with a blank canvas and gradually revealing a masterpiece—one brushstroke at a time. By harnessing the power of numbers and strategic content highlighting, diffusion models showcase how simplicity can lead to richness.
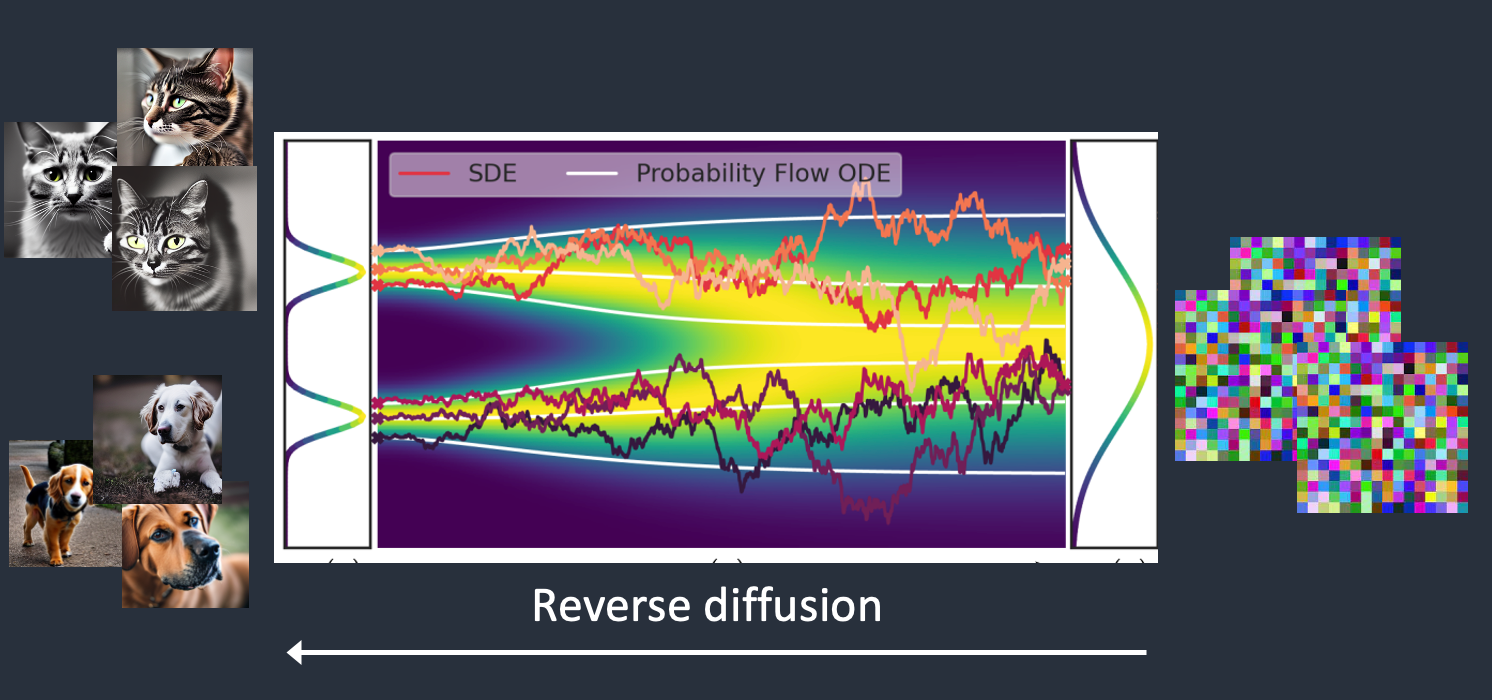
Reverse Diffusion and Meaningful image
What Sets It Apart?: The reverse diffusion process distinguishes diffusion models from other generative counterparts (think GANs).
Here’s the twist: We recognize noise patterns introduced at each step during forward diffusion.
From Noise to Meaning: Our model, armed with acquired wisdom, predicts noise patterns at each step. With surgical precision, it carefully removes noise, like an art restorer revealing hidden details. The result? A meaningful image emerges—a face, a landscape, or a dreamlike abstraction.
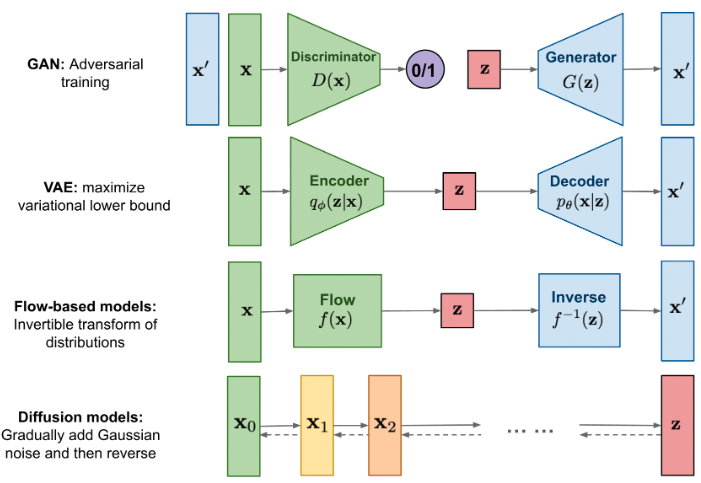
In a Nutshell: Diffusion Models vs. GANs
When it comes to training and generating data, diffusion models and GANs take different paths. Here’s the breakdown:
Diffusion Models:
- Approach: These models refine their output step by step, akin to a painter adding brush strokes to a canvas.
- Stability: The gradual process makes diffusion models more stable during training and generation.
- Resilience: Their deliberate progression helps them handle uncertainty better than GANs.
- Model Requirement: Only one model is needed for both training and generation.
Generative Adversarial Networks (GANs):
- Approach: GANs leap from noise to an image in one go, much like a magician pulling a rabbit out of a hat.
- Instantaneous: This quick approach can lead to instability during training.
- Complexity: GANs require a more intricate architecture.
In summary, diffusion models take it slow and steady, while GANs go for the magic trick. Each has its strengths, but diffusion models win points for stability and simplicity.
What are the Applications of Diffusion Models?
The application of diffusion models exhibits extraordinary versatility and potential across multiple scenarios. Diffusion models have emerged as a powerful family of deep generative models, achieving record-breaking performance in various applications. Let’s delve into their versatile uses:
- Image Synthesis and Video Generation: Diffusion models excel in generating realistic images and videos. By modeling the gradual diffusion process, they create high-quality content.
- Molecule Design: In drug discovery and materials science, diffusion models aid in designing novel molecules with desired properties. They explore chemical space efficiently.
- Natural Language Generation: These models generate coherent and contextually relevant text. Applications include text completion, dialogue systems, and language translation.
- Multi-Modal Learning: Combining information from different modalities (e.g., text and images) benefits tasks like image captioning and cross-modal retrieval.
- Molecular Graph Modeling: In chemistry, diffusion models predict molecular properties and generate molecular graphs.
- Material Design: Diffusion models aid in designing new materials with desired properties, such as strength, conductivity, or transparency.
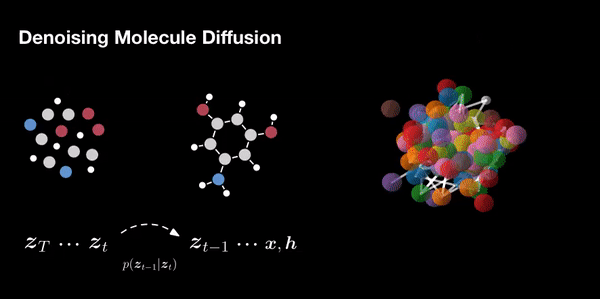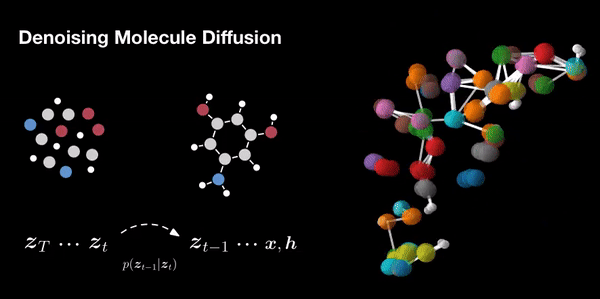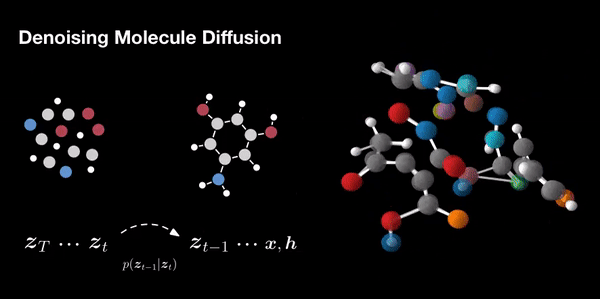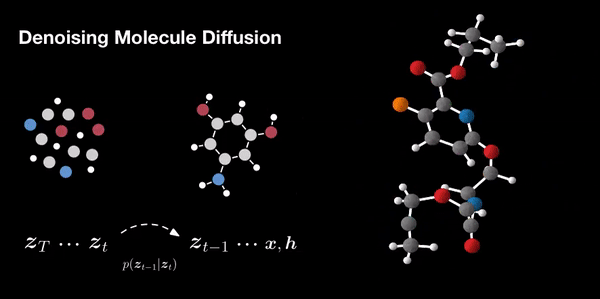
Additionally, they can be combined with other generative models for even better results. The field of diffusion models continues to evolve, offering exciting avenues for exploration and innovation.
Stable Diffusion represents the latest leap in unsupervised image generation. While complex under the hood, Stable Diffusion provides a surprisingly intuitive interface. Users can easily experiment by typing descriptions to envision scenes, people, objects or concepts. The results often feel limited only by one's imagination!
I hope this quick overview gives you a sense of how Stable Diffusion is redrawing the frontiers of AI artistry through its unprecedented combination of capability and ease of use. Keep your eyes peeled for what comes next as the model evolves!