
🔍 Adopting and Fine-Tuning Large Language Models for Specific Domain Industry Tasks in Business
3 July, 2023
The field of natural language processing (NLP) has witnessed significant advancements with the rise of large language models (LLMs) and transfer learning. Fine-tuning a pre-trained language model has become the standard approach for leveraging transfer learning in NLP tasks. This process allows us to take advantage of the knowledge and context captured by pre-trained models and adapt them to specific tasks or domains. In this article, we will explore the concept of fine-tuning LLMs for specific domain industry tasks in the business world and discuss its benefits and applications.
Fine-Tuning and Transfer Learning
🔗 Transfer learning involves taking a pre-trained language model and fine-tuning it on a specific task or dataset. By training LLMs on smaller, more specific datasets, they can specialize in a particular area and provide more accurate responses. The advantage of fine-tuning is that it can be done comparatively inexpensively, as opposed to the compute-intensive pre-training process.
Domain Adaptation and Boosting Performance
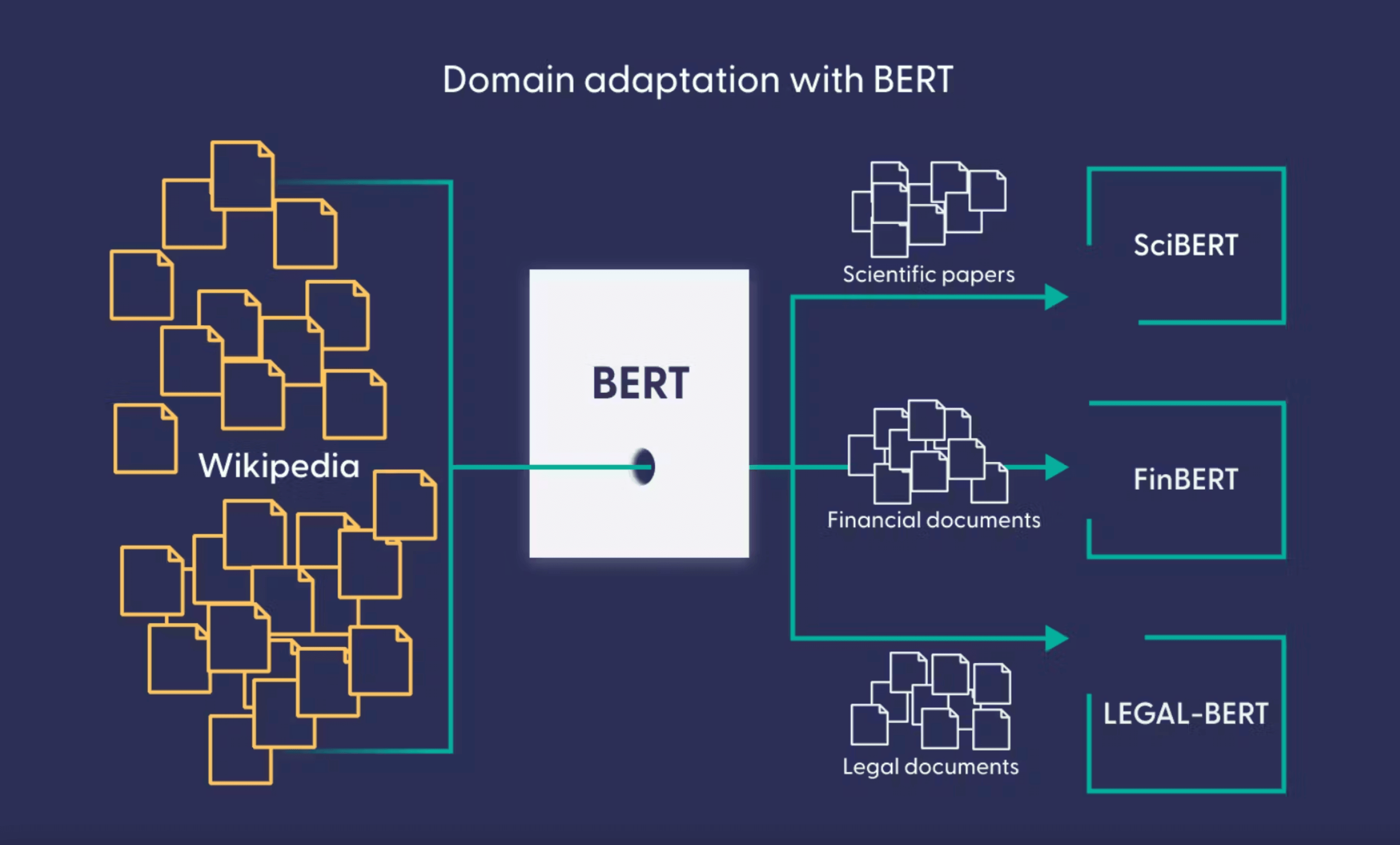
In many NLP applications, a pre-trained model from the Hugging Face Hub can be directly fine-tuned on the target data for the task at hand. However, there are cases where fine-tuning on in-domain data becomes necessary for optimal performance. For example, if the dataset contains legal contracts or scientific articles, a vanilla Transformer model like BERT may struggle with domain-specific words, resulting in subpar performance. By fine-tuning the language model on in-domain data, we can enhance the model's performance for downstream tasks in that domain.
🏢 Professional domains, such as medicine or law, often employ highly specialized jargon that is difficult for non-experts to understand. When a general-purpose LLM is applied to process data from these domains, it may underperform, just like a person without domain expertise. Domain adaptation provides a solution to this challenge. By fine-tuning the pre-trained model on specialized data, such as legal documents or medical papers, we can improve its ability to comprehend and generate domain-specific language.
Advancements in Transfer Learning with All Layer Updating
Recent developments in transfer learning have seen a shift from masked language models like BERT and RoBERTa to autoregressive models of language, such as T5 and GPT-3. These models provide a more comprehensive understanding of language and enable more sophisticated fine-tuning approaches.
🔄 While the original BERT paper suggested that fine-tuning only the output layer can yield comparable results, updating all layers of the pre-trained LLM usually leads to superior performance. Although updating all layers involves more parameters and computational resources, it consistently produces better modeling results. By freezing the pretrained LLM's parameters and finetuning them along with the additional layers, we can optimize the model's performance for specific tasks.
Parameter-Efficient Finetuning to Maximize Efficiency and Performance
Parameter-efficient finetuning is a valuable approach that allows us to reuse pretrained models while minimizing computational and resource requirements. There are five key benefits to parameter-efficient finetuning:
💻 Reduced computational costs. Fewer GPUs and less GPU time are needed.
⏭️🏃 Faster training times. Training finishes more quickly.
🖥️ Lower hardware requirements. Works with smaller GPUs and requires less memory.
🎯 Better modeling performance. Reduces overfitting.
💾 Less storage. Weight sharing across different tasks reduces storage needs.
While finetuning more layers typically leads to better results, it becomes challenging with larger models that barely fit into GPU memory, such as the latest generative LLMs. However, researchers have developed parameter-efficient finetuning techniques that achieve high modeling performance by training only a small number of additional parameters.
These techniques, including prefix tuning, adapters, and low-rank adaptation, introduce a small number of additional parameters that are finetuned. This differs from the traditional finetuning approach where all layers are updated. Techniques like prefix tuning, adapters, and low-rank adaptation modify multiple layers and achieve superior predictive performance at a low cost.
Reinforcement Learning with Human Feedback
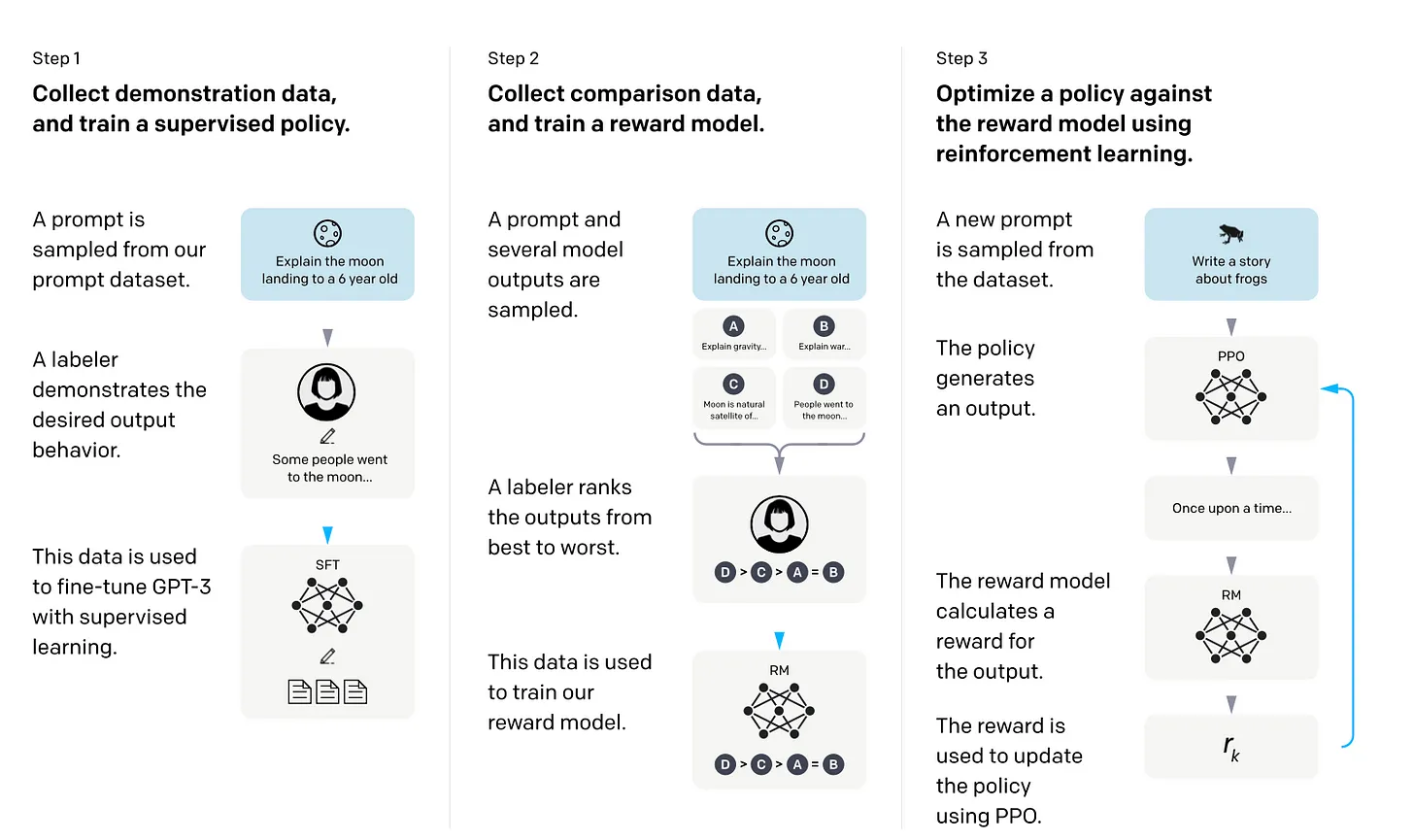
Reinforcement Learning with Human Feedback (RLHF) offers an alternative approach to fine-tuning LLMs by incorporating human preferences. In RLHF, pretrained models are fine-tuned using a combination of supervised learning and reinforcement learning techniques. Human feedback, collected through rankings or ratings of model outputs, serves as a reward signal for training a reward model. The reward model is then utilized to guide the LLM's adaptation to human preferences.
Using a reward model instead of directly training the pretrained model with human feedback avoids the bottleneck of real-time human evaluation during inference. Proximal Policy Optimization (PPO), a reinforcement learning algorithm, is often employed to fine-tune the LLM's parameters based on the reward model.
Conclusion
Fine-tuning all layers of a pretrained LLM remains the gold standard for adapting to new target tasks. However, there are several efficient alternatives for using pretrained transformers, including feature-based approaches, in-context learning, and parameter-efficient finetuning techniques. These methods enable effective application of LLMs to new tasks while minimizing computational costs and resources.
Reinforcement learning with human feedback (RLHF) offers a promising avenue for further enhancing model performance by incorporating human preferences into the fine-tuning process. RLHF combines supervised learning, reinforcement learning, and reward models to optimize LLMs for specific tasks based on human rankings and ratings.
🚀 As the field of NLP continues to evolve, adopting and fine-tuning large language models for specific domain industry tasks in business holds great potential for improving efficiency, accuracy, and domain expertise in various applications.