
Fine Tuning Large Language Models
9 September, 2023
Fine-tuning is the process of taking an already-trained model and giving it a makeover to tackle a similar task. When a model needs tweaks for a new job or isn't performing up to par, fine-tuning comes to the rescue.
How Fine-tuning Works
Fine-tuning takes the original model's weights and molds them to fit the new task. For instance, consider GPT-3, a model trained on a massive dataset, mastering various skills like generating stories, poems, songs, and more.
Mastering Transfer Learning
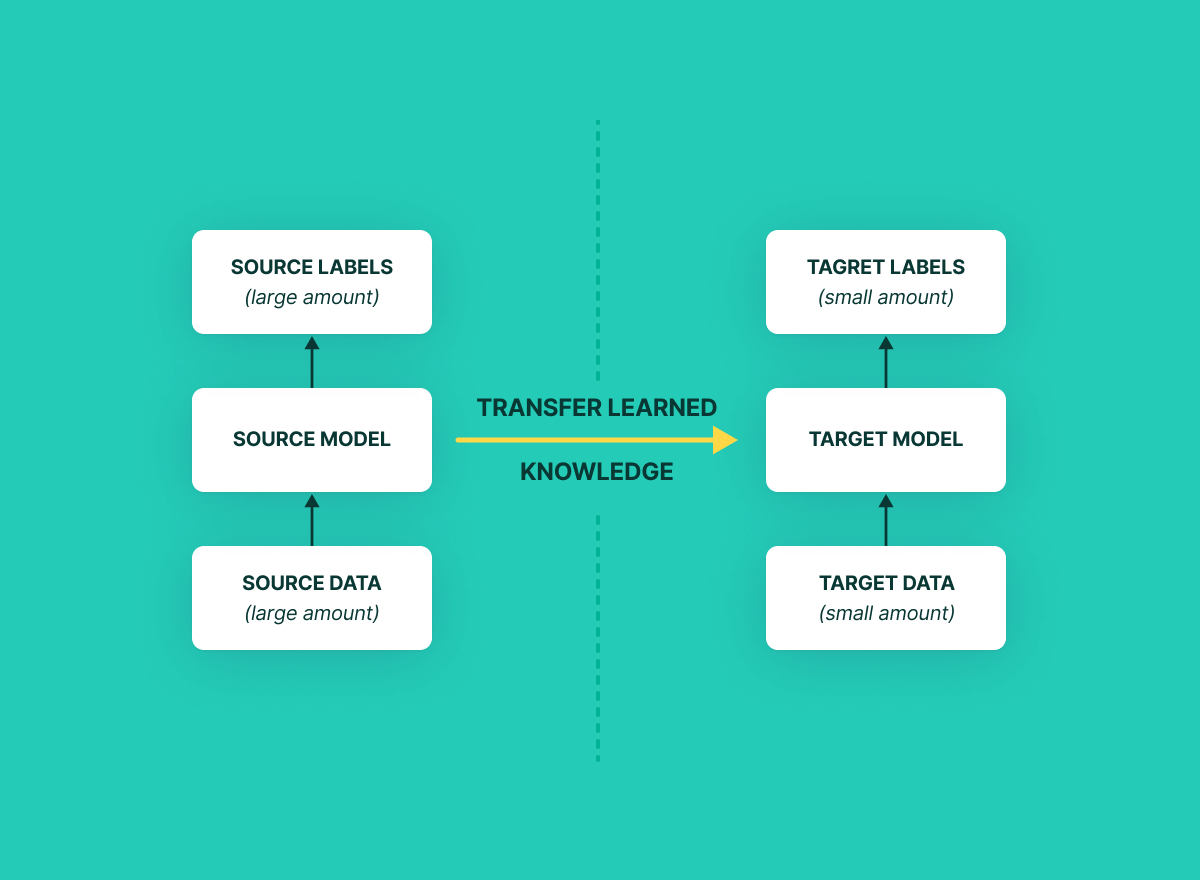
Transfer learning, borrowed from the world of computer vision, simplifies fine-tuning. It involves freezing the initial layers of a network (the ones close to the input) and updating only the later layers (closer to the output).
In Context Learning
Before diving into the intricacies of fine-tuning methods, it's crucial to introduce the concept of in-context learning, including the innovative approach of indexing.
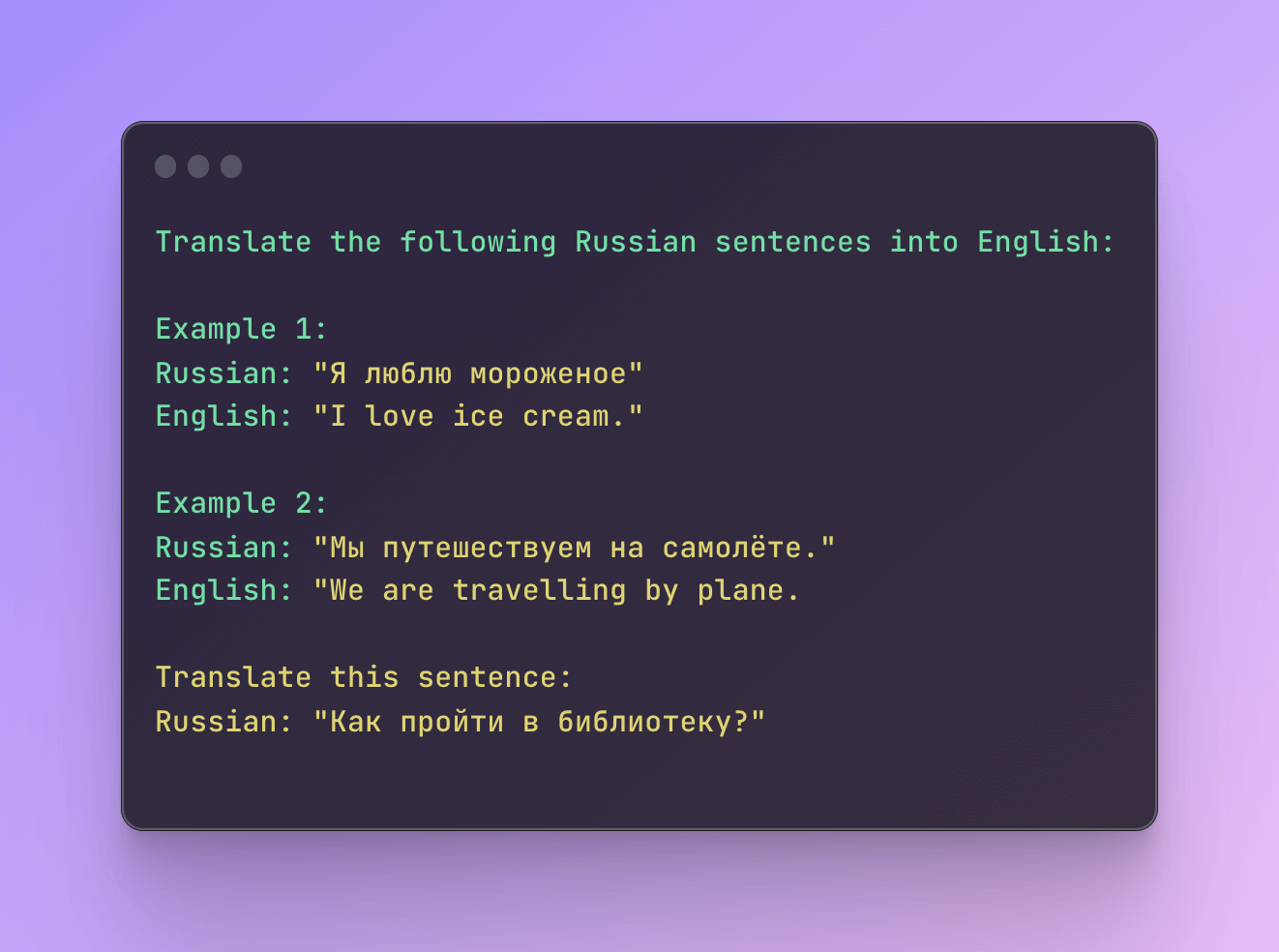
Prompting and In-Context Learning
Since the advent of GPT-3, it's clear that large language models (LLMs) are masters of in-context learning. No need for extensive training or fine-tuning for specific tasks. Just feed them a few task examples, and they'll deliver. Perfect for API users.
Hard Prompt Tuning
When we tweak the input directly for better results, it's called "hard" prompt tuning. We'll delve into a softer version later. Hard prompt tuning is about making the input work smarter.

Efficiency with Some Trade-offs
While hard prompt tuning saves resources compared to full parameter fine-tuning, it might not match the performance. It doesn't fine-tune the model's parameters for task specifics. Plus, it can be a hands-on process, comparing prompts to ensure quality.
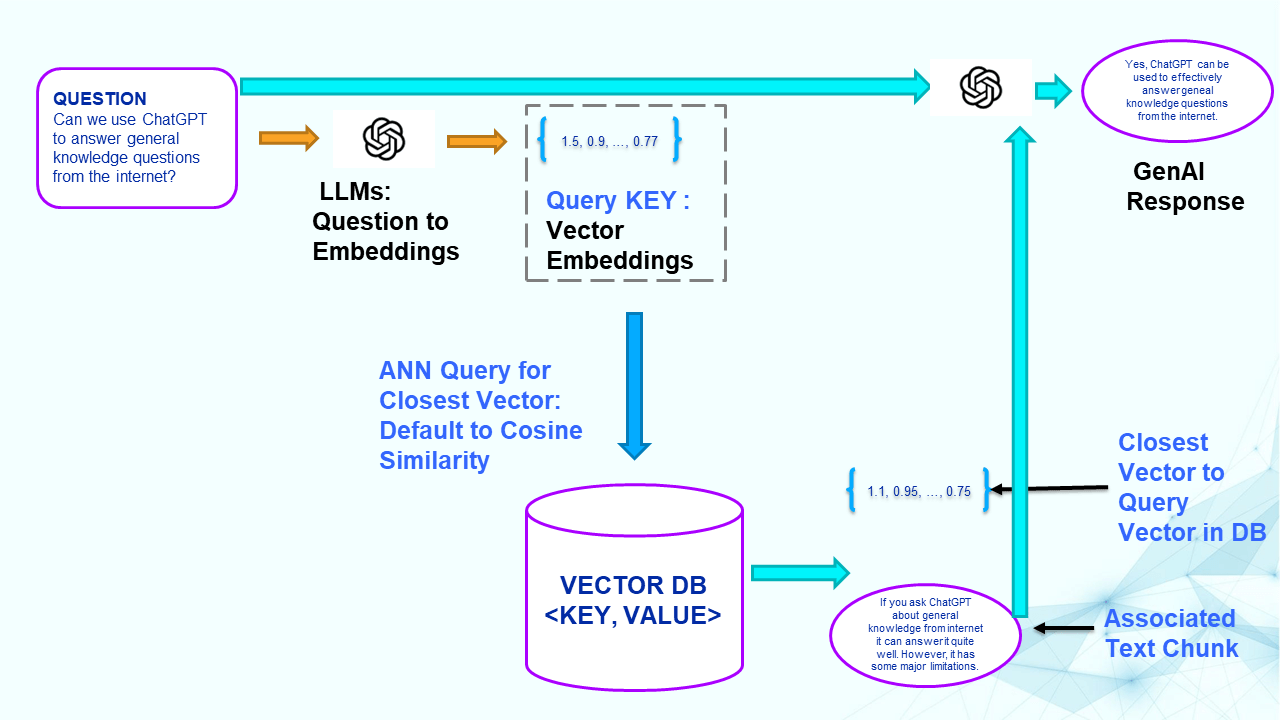
The Magic of Indexing
Another way to tap into in-context learning is through indexing. Think of it as LLMs transformed into data-mining wizards. The process involves breaking down web content, converting it into vectors, and storing these in a database. When you ask a question, the indexing module finds the most relevant embeddings to generate answers. A seamless way to extract data from external sources.
Prompting vs Fine Tuning
Prompting is about adapting a model in real-time as it interacts with specific user inputs or context. Fine-tuning involves taking a pre-trained model, typically on a large dataset (e.g., a pre-trained language model like GPT-3), and further training it on a specific, smaller dataset for a particular task.
Layer Update Fine-Tuning Methods
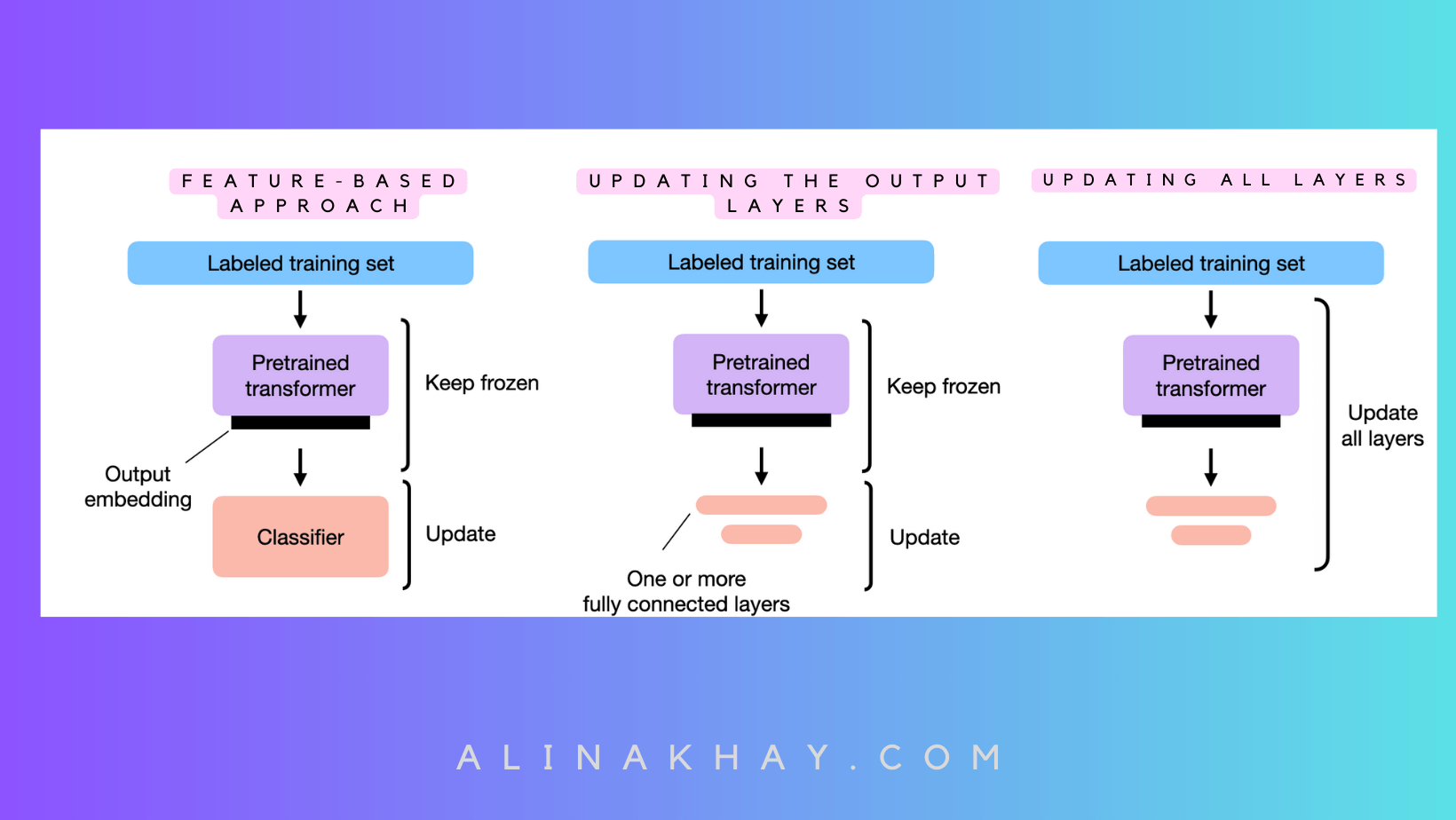
In the realm of Large Language Models (LLMs), adapting them to specific tasks is crucial for optimal performance. While in-context learning suits scenarios with limited LLM access, having full access opens the door to three conventional methods.
Feature-Based Approach
Fine-tuning an encoder-style LLM like BERT can significantly boost performance for classification tasks. In a simple example, we determine whether a movie review carries a positive or negative sentiment.
Decoder-Style LLMs Unleashed
This approach isn't limited to encoder-style LLMs; decoder-style models like GPT can also shine. They're versatile, handling tasks like generating multi-sentence responses to specific instructions, not just classifying text.
Efficient Fine-Tuning: Updating Output Layers
An effective method closely related to the feature-based approach is fine-tuning the output layers, which we'll call "fine-tuning I." Here's how it works:
We keep the pretrained Large Language Model's (LLM) parameters untouched.
We focus our training efforts solely on the newly introduced output layers. Think of it like training a logistic regression classifier or a compact multilayer perceptron on the embedded features.
In Practice
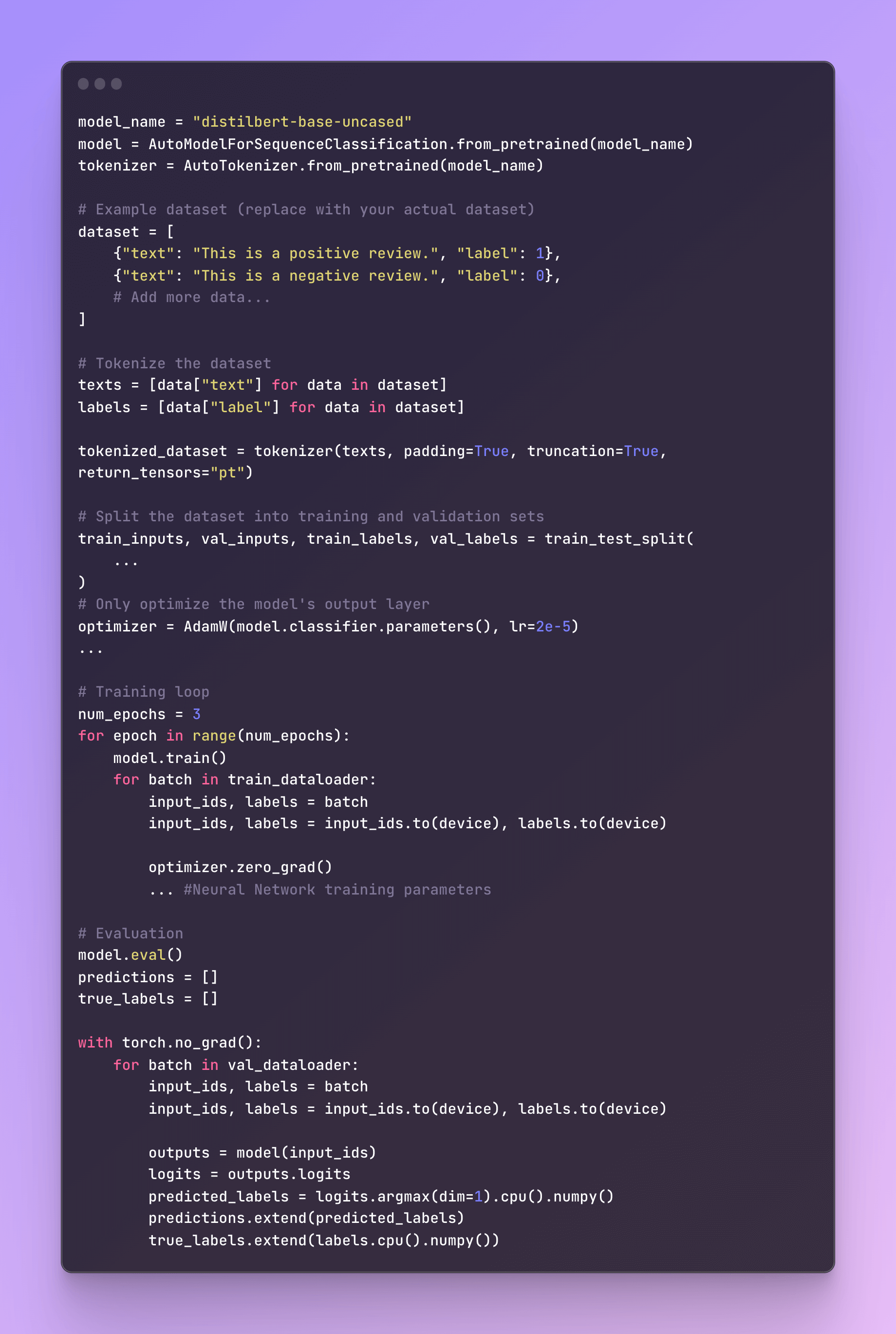
In code, it's as straightforward as it sounds:
Comparable Performance
In theory, this approach delivers performance and speed akin to the feature-based method because both rely on the same frozen backbone model. However, the feature-based approach might have an edge in some practical situations due to its simplicity in pre-computing and storing embedded features for the training dataset.
Fine-tuning by Updating All Layers
In the world of fine-tuning, there's another strategy that deserves a spotlight - fine-tuning all layers, affectionately known as "fine-tuning II.”
Performance vs. Parameters
The original BERT paper showed that fine-tuning just the output layer can yield comparable performance to fine-tuning all layers. However, fine-tuning all layers involves a lot more parameters. For example, a BERT base model boasts around 110 million parameters, with a mere 1,500 in the final layer. Even the last two layers account for just 60,000 parameters - a fraction of the total.
Performance Matters
In practice, fine-tuning all layers usually trumps the competition in terms of modeling performance. It's the gold standard for squeezing the most out of pretrained Large Language Models (LLMs). The key difference is that we don't lock down the pretrained LLM's parameters; we fine-tune everything.
Code Insight
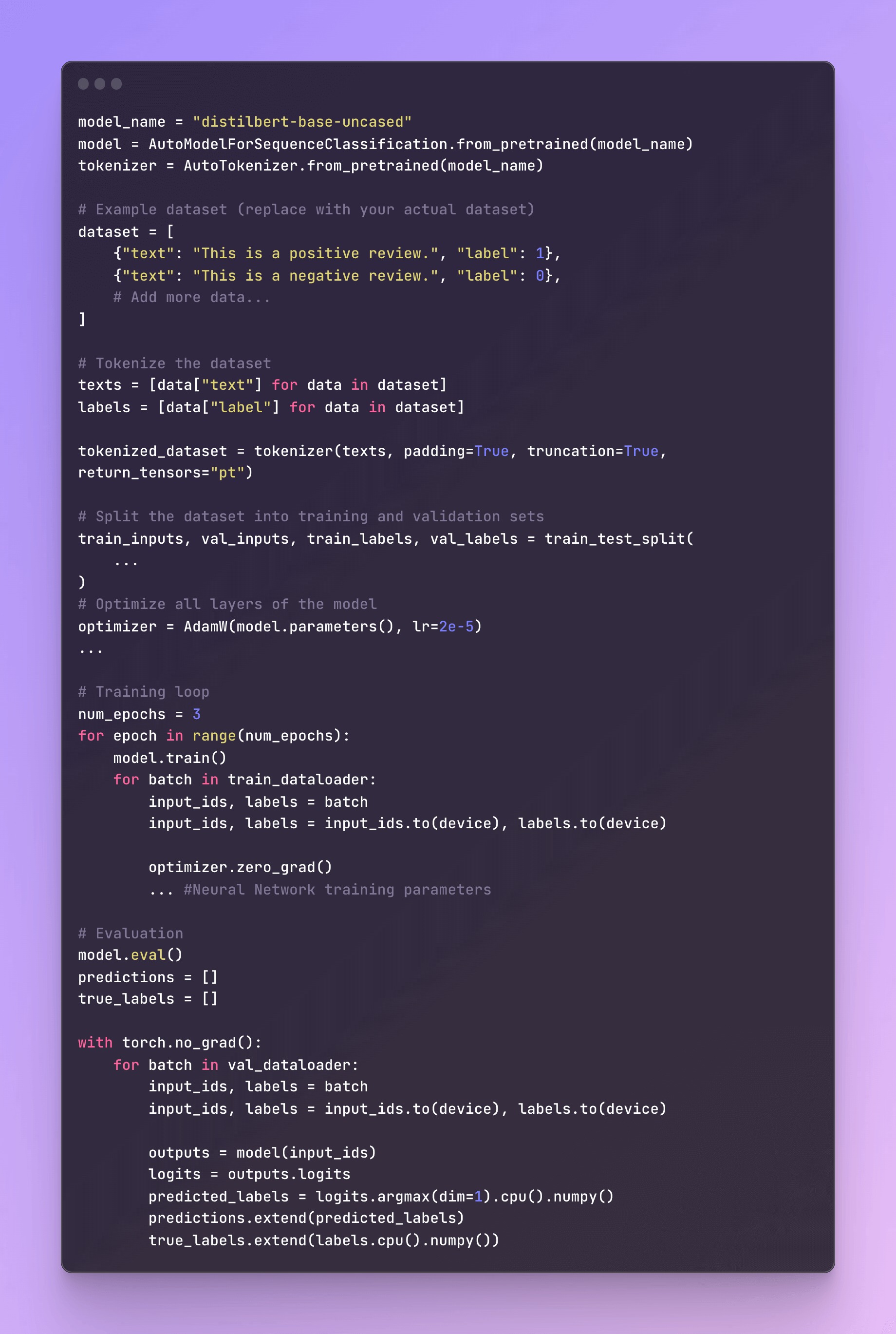
Remember, the more layers you fine-tune, the better the performance, but also the higher the cost.
Visualizing Performance
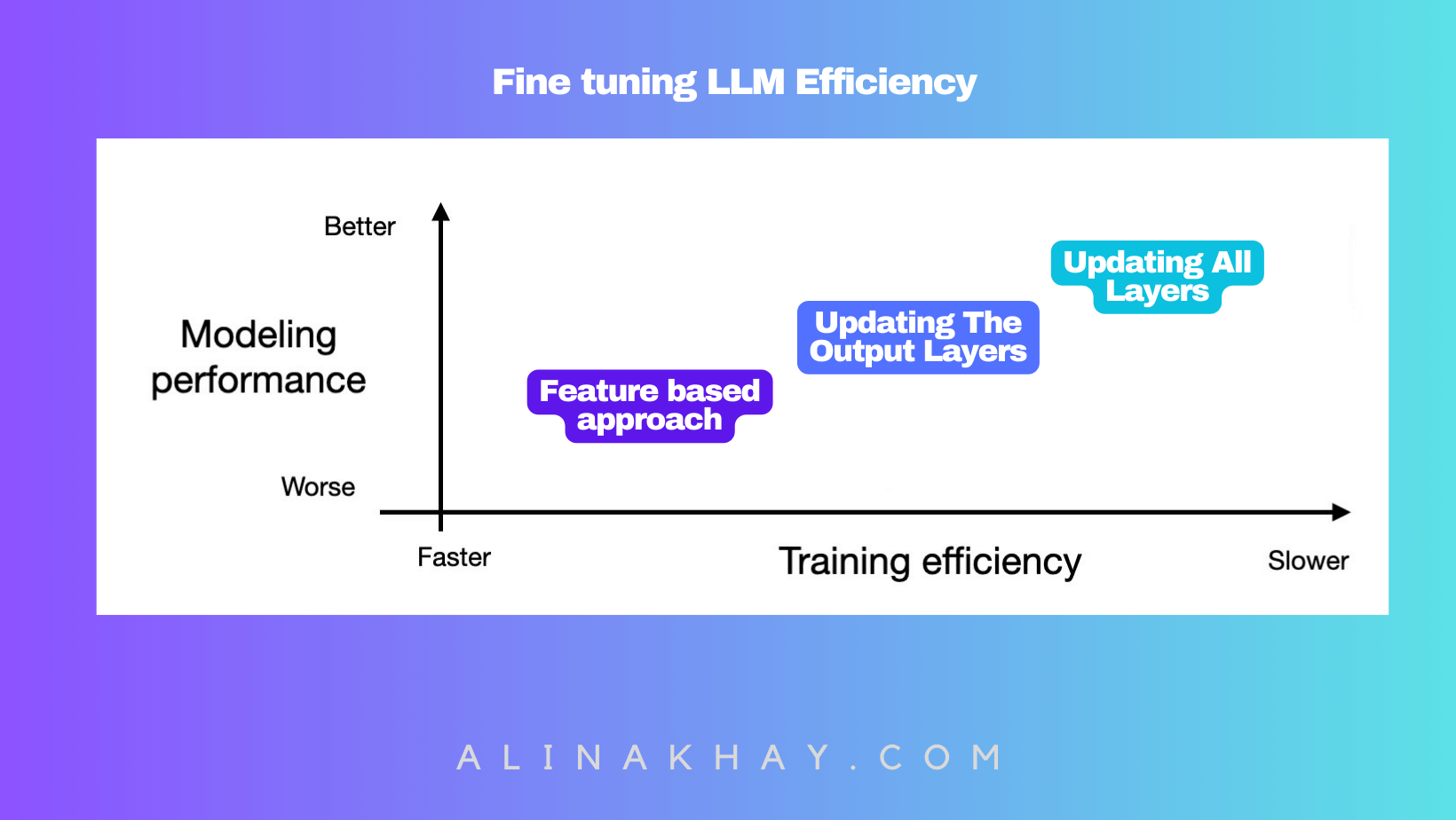
Don't forget the middle ground. Sometimes, fine-tuning just half the model can deliver similar results. It's all about striking the right balance.
In this DistilBERT example, we see that training only the last layer is the quickest but yields the poorest performance. As you fine-tune more layers, performance improves, but computational costs climb. Fine-tuning - it's all about finding that sweet spot.
Parameter Efficient Fine-Tuning
In the world of AI, Parameter Efficient Fine-Tuning (PEFT) is a game-changer. It's a set of savvy techniques designed to fine-tune large models in a way that's both time and cost-efficient. The goal? Preserve performance without the hefty compute price tag.
The Challenge of Gigantic Models
Models like BLOOM, flaunting a staggering 176 billion parameters, pose a challenge. Fine-tuning them traditionally would drain your pockets with tens of thousands of dollars. Yet, these colossal models often deliver superior performance, making them essential.
Parameter-Efficient Fine-Tuning: Maximizing Benefits
Parameter-efficient fine-tuning is a game-changer in the AI world, offering a multitude of advantages. Here are five compelling reasons why it's a must-have:
- Cost Savings: Reduced computational costs mean you need fewer GPUs and less GPU time, saving precious resources.
- Speed Demon: Faster training times ensure you finish your AI training sessions more quickly, boosting productivity.
- Lean Hardware: Lower hardware requirements mean you can work with smaller GPUs and less memory, making AI accessible to more setups.
- Top-Notch Performance: Parameter-efficient fine-tuning helps prevent overfitting, resulting in better modeling performance.
- Storage Efficiency: It's efficient in terms of storage, as most weights can be shared across various tasks.
Now, consider the scenario where you're dealing with larger models that barely fit into GPU memory, like the latest generative Large Language Models (LLMs). You can employ the feature-based or fine-tuning I approach, but what if you want modeling quality similar to fine-tuning II? Let's explore this challenge.
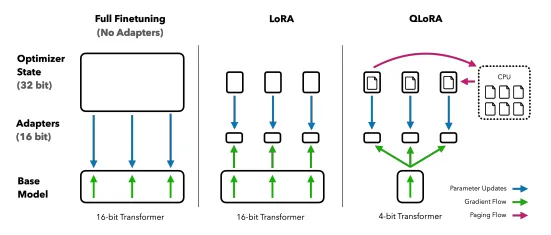
LoRA: Streamlining Fine-Tuning for Efficiency
Efficient Parameter Fine-Tuning Parameter-efficient fine-tuning techniques are here to simplify and streamline the fine-tuning process. Instead of tweaking all model parameters, they introduce a clever workaround.
The LoRA Advantage
Meet LoRA, the master of efficiency. It slashes the number of trainable parameters by a whopping 10,000 times and trims GPU memory requirements by 3 times, all without adding any pesky inference delays.
How LoRA Works
LoRA's secret lies in its selective parameter tweaking. Here's the lowdown:
- Identify Key Parameters: LoRA pinpoints the vital parameters necessary for the specific task at hand.
- Low-Rank Matrices Magic: It introduces compact low-rank matrices into each layer of the pre-trained model. These matrices are simpler and more manageable than the original weight matrices, perfect for fine-tuning.
- Fine-Tuning Focus: LoRA fine-tunes these low-rank matrices while keeping the rest of the model's parameters locked in place.
Next up QLoRA
In May 2023, QLoRA made its debut. It's a quantized version of the Low-rank adapter technique, focusing on reducing precision for enhanced neural network efficiency.
Reinforcement Learning with Human Feedback (RLHF)
RLHF, an ingenious approach, enhances pretrained models using a blend of supervised and reinforcement learning. The inspiration behind this method can be traced back to the ChatGPT model, which, in turn, drew from InstructGPT.
Human Feedback as the North Star
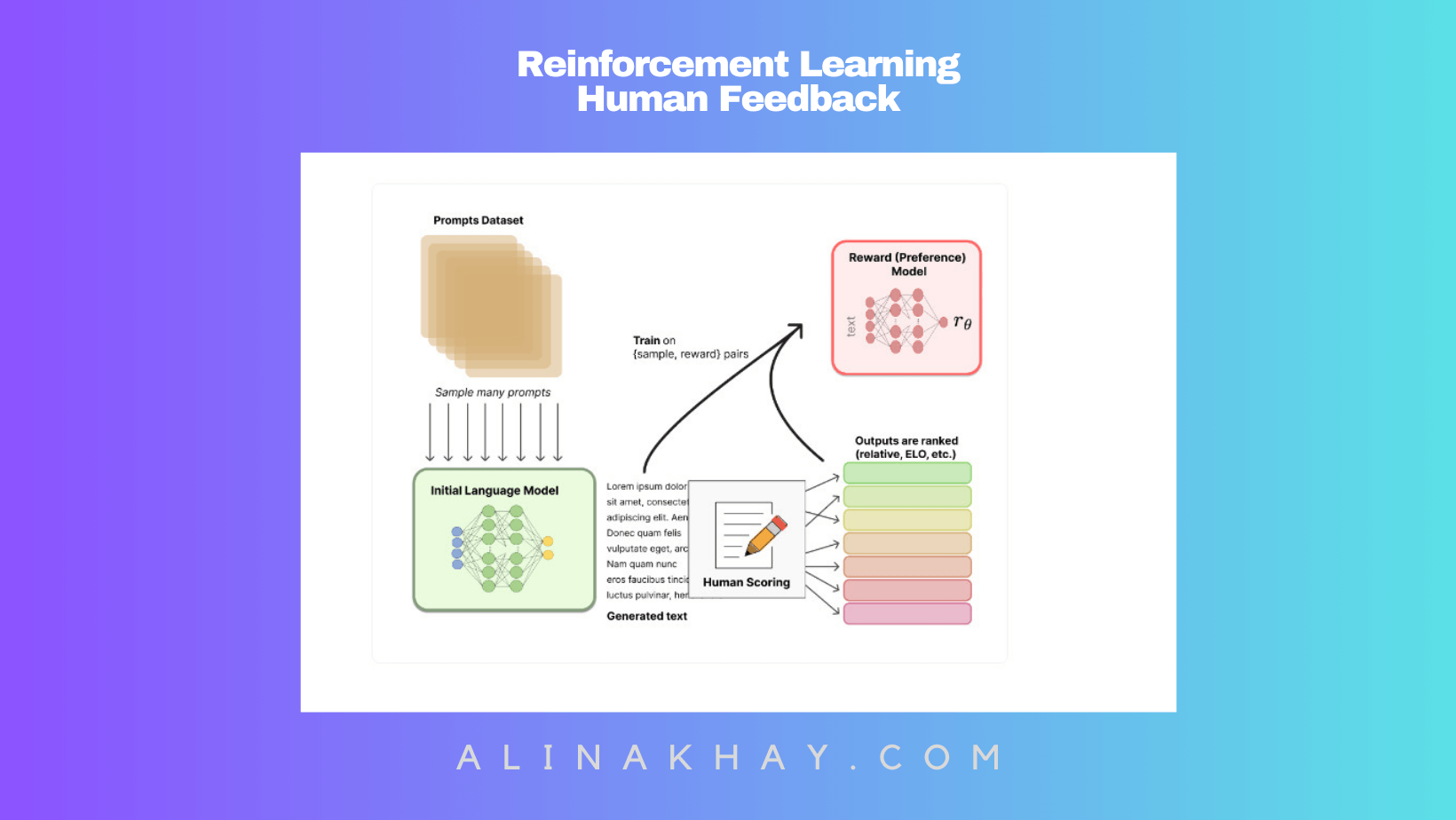
In RLHF, humans play a vital role by ranking or rating different model outputs, creating a valuable reward signal. These reward labels serve as the guiding light for fine-tuning the Large Language Models (LLMs) to align with human preferences.
The Reward Model's Journey
The journey begins with a reward model, educated through supervised learning (often using a pretrained LLM as the foundation). Then, this reward model steps up to train the pretrained LLM, a process powered by proximal policy optimization.
Why Not Direct Feedback?
Using a reward model is a strategic choice. Gathering real-time human feedback would slow things down significantly, creating bottlenecks in the learning process.
Shifting the Training Paradigm
In today's world, building deep learning models from the ground up for text or vision tasks is often inefficient. Instead, we harness pretrained models and fine-tune them. This approach not only saves time and computational resources but also delivers superior performance.
A Case in Point: ViT Architecture
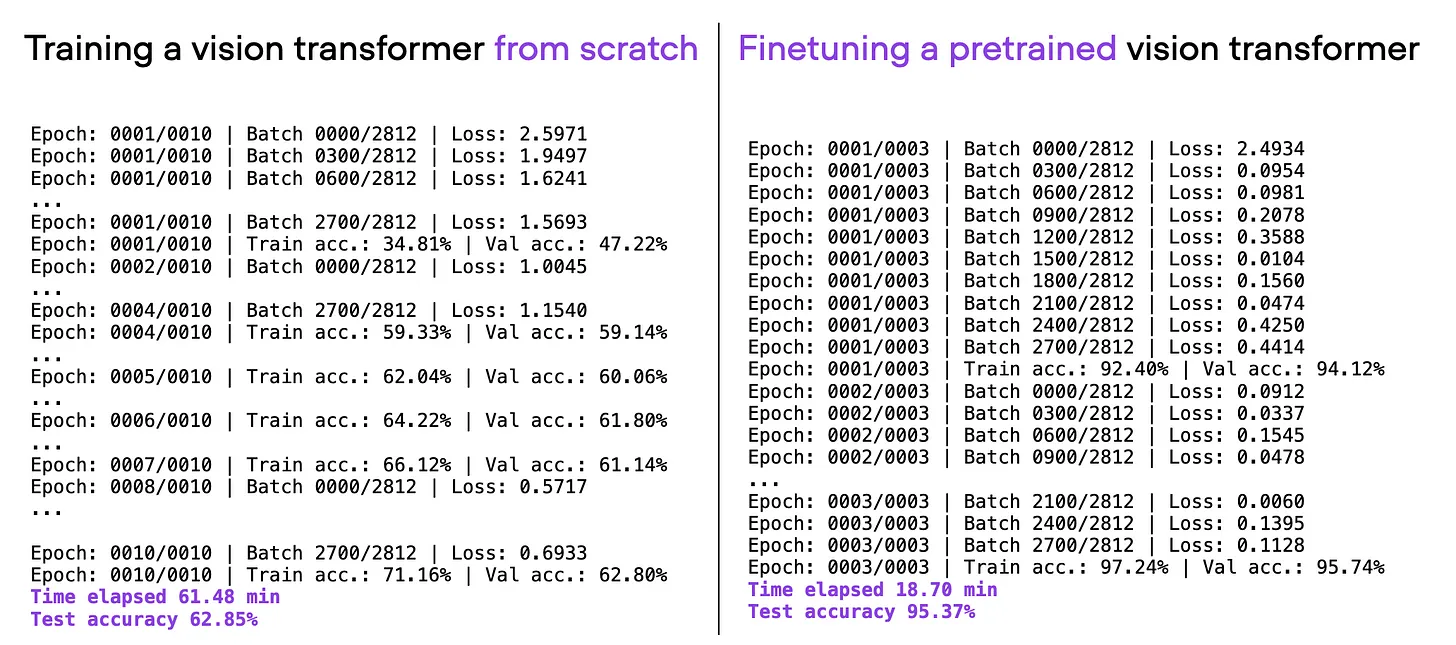
Take, for example, the Vision Transformer (ViT) architecture. When we fine-tune a pretrained ViT model (originally trained on ImageNet) for our specific needs, magic happens. In just 20 minutes and 3 training epochs, we achieve a remarkable 95% test accuracy, outshining training from scratch by a wide margin.
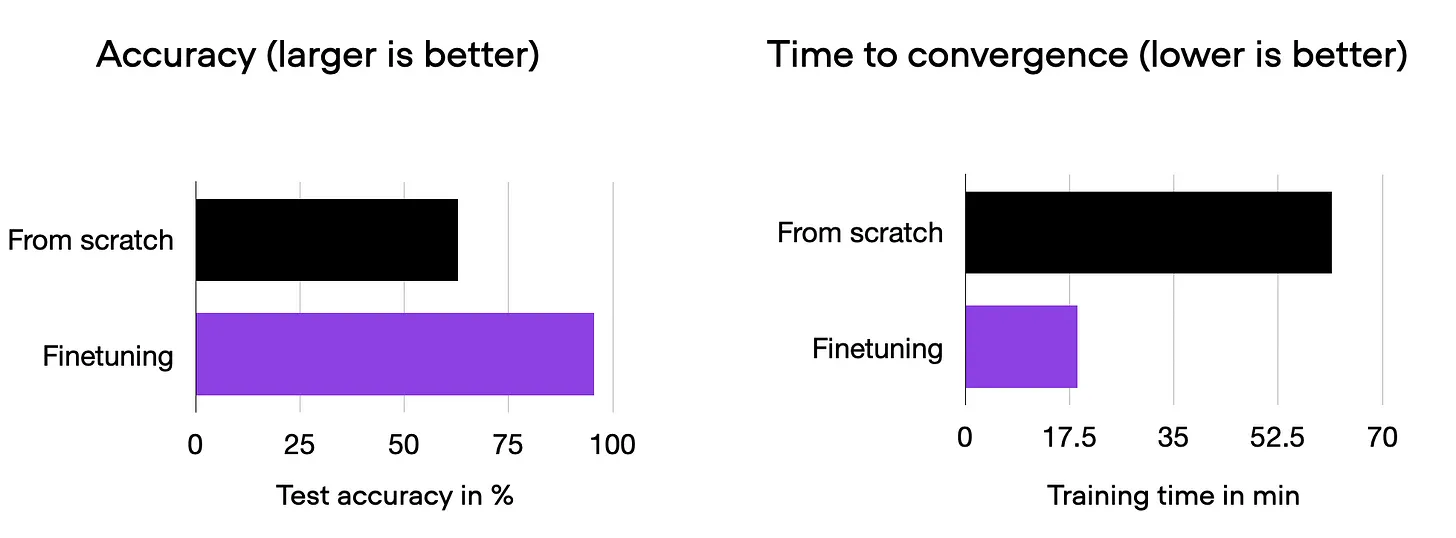
As illustrated above, fine-tuning proves its worth, offering a substantial boost over starting from scratch. While results may vary depending on the dataset or task, for many text and vision assignments, kickstarting with a pretrained model is the smart choice.
Conclusion
Fine-tuning all layers of a pretrained LLM remains the gold standard for adapting to new target tasks, but there are several efficient alternatives for using pretrained transformers. Methods such as feature-based approaches, in-context learning, and parameter-efficient fine-tuning techniques enable effective application of LLMs to new tasks while minimizing computational costs and resources.