
Future of LLMs
18 October, 2023
The GPU shortage is showing signs of improvement. Tech giants like Amazon, Google, and Microsoft are stepping up to challenge Nvidia with their own GPU-friendly chips.
The Rise of Compact Models
A noteworthy trend is the shift towards smaller models that deliver big performance. For instance, Mistral's 7B model outperforms the 13B version, and Llama-2 70B can be fine-tuned to match the performance of GPT-3.5 (180B).
Mixture of Experts (MOE) Architecture
The future may lie in MOE architecture, where open-source models are finely tuned for specific tasks. This ensemble of "expert" models has the potential to achieve GPT-4-like performance. With each model being under 100B in size, they become accessible for research and mass-market use, even for those with limited GPU resources.
Microsoft's DeepSpeed team, part of the AI at Scale initiative, explores MoE model applications and optimizations at scale. They were able to cut training cost by 5x, resulting in up to 4.5x faster and 9x cheaper inference for MoE models compared to quality-equivalent dense models.
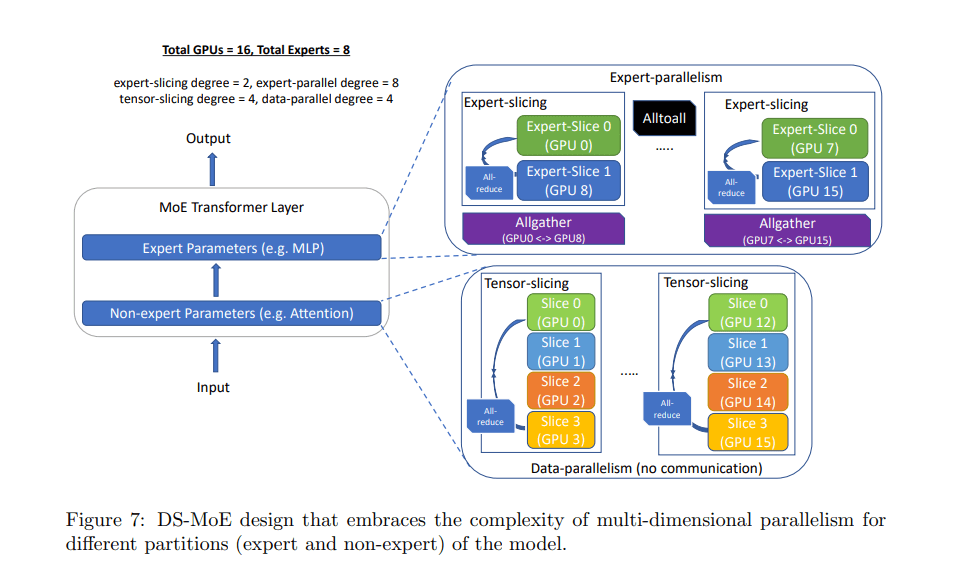
Cost and Accessibility
Serving super large models is not just costly but also cumbersome. Models like Llama-2, under 100B in size, show promise in resolving the GPU crunch. Multiple players entering the market and more efficient models are expected to alleviate the GPU shortage.
The Role of Data in Enhancing LLM Performance
Expanding Training Datasets
Can expanding the training datasets of Large Language Models (LLMs) lead to improved performance? This question is vital to consider.
Plateau Effect
Is it possible for OpenAI to endlessly train more powerful and high-performing models in an infinite loop? LLMs reach a performance plateau when they've exhausted the information in their training data. This implies that we can exhaust our "training data."
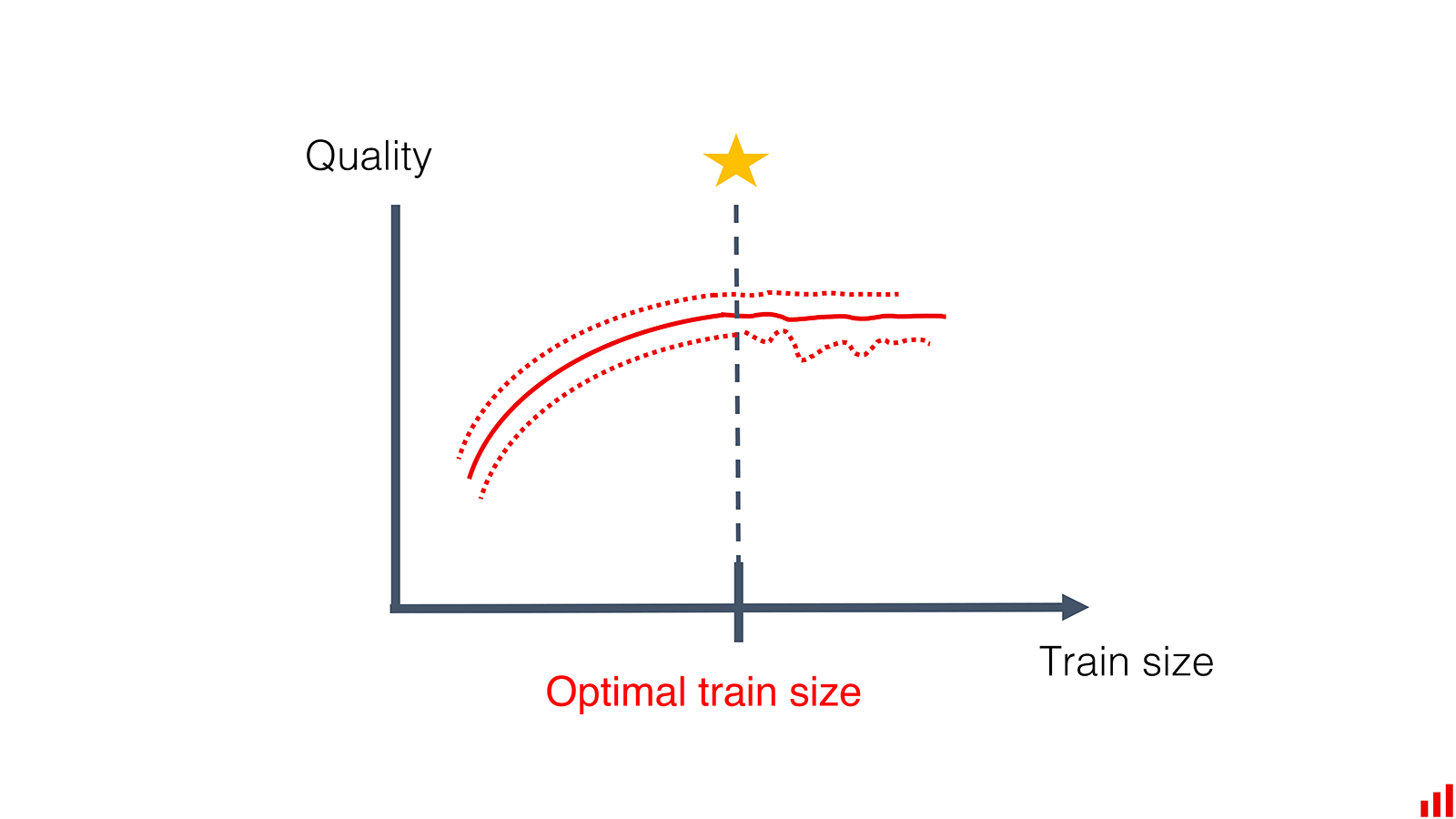
Saturation of Training Data
In conventional machine learning, performance doesn't improve, even with larger datasets, as long as the sample is robust and reflects the data distribution. Some argue that we've already reached the limits of available training data. This suggests that GPT-5, 6, and 7 may resemble GPT-4, unless new techniques are developed.
Endless Data Generation
However, humans and LLMs are continually generating a vast amount of new data. In this sense, we may never run out of fresh data for LLM training.
Balancing Data and LLM Size
Scaling LLMs with Data
Do we need increasingly larger LLMs as we generate more training data? This is a critical question.
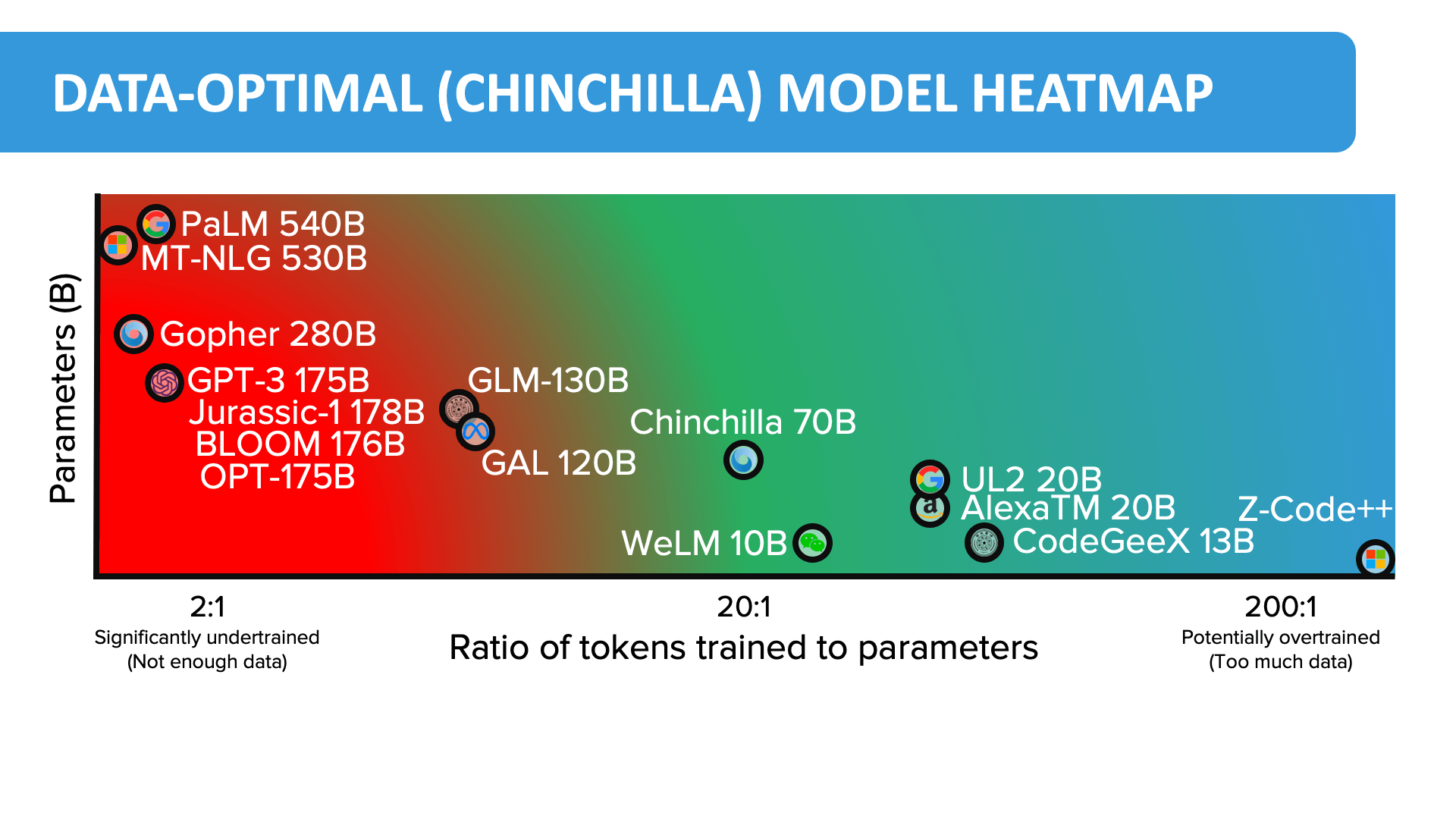
The Chinchilla Training Law
Google's Chinchilla Training Law challenges traditional scaling laws. It advocates for a ~21:1 ratio of training tokens to parameter size, a departure from the conventional ~1:1 ratio. This optimized ratio considers model size, training data, and compute budget.
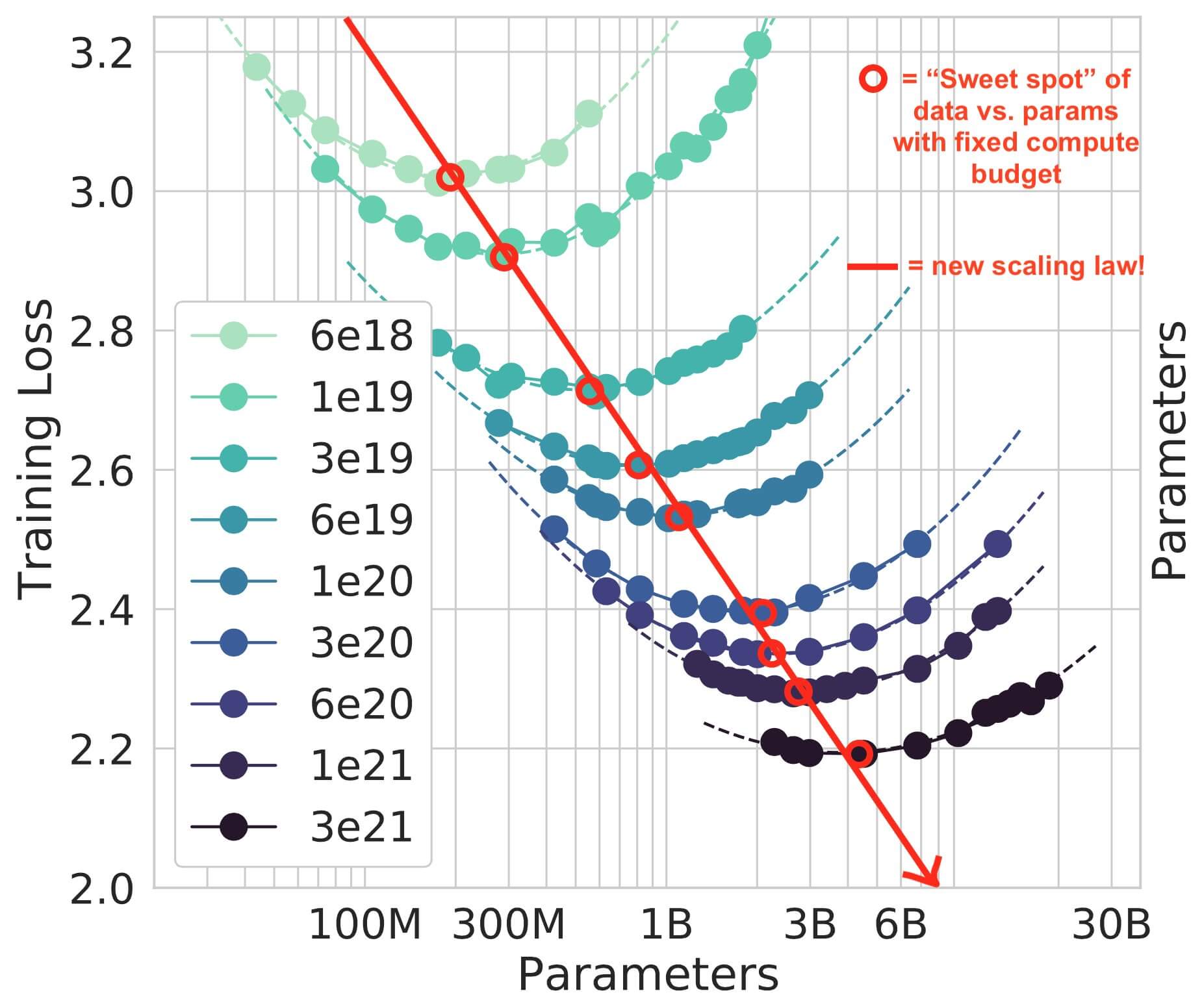
Optimizing Efficiency
This law argues that many models have been "massively oversized and massively undertrained." It points toward more efficiently trained and cost-effective Large Language Models.
Data-Optimal Training
To achieve data-optimal training, LLMs with 70 billion parameters should be trained with a staggering 1,400 billion (1.4 trillion) tokens. For instance, Llama-2 70B is trained on 2 trillion tokens. Size vs. Data: More data doesn't necessarily mean bigger LLMs. The key lies in finding the right balance.
Data Quality and LLM Performance
Quality Over Quantity
Just like in standard machine learning, prioritizing data quality over quantity can significantly enhance LLM performance.
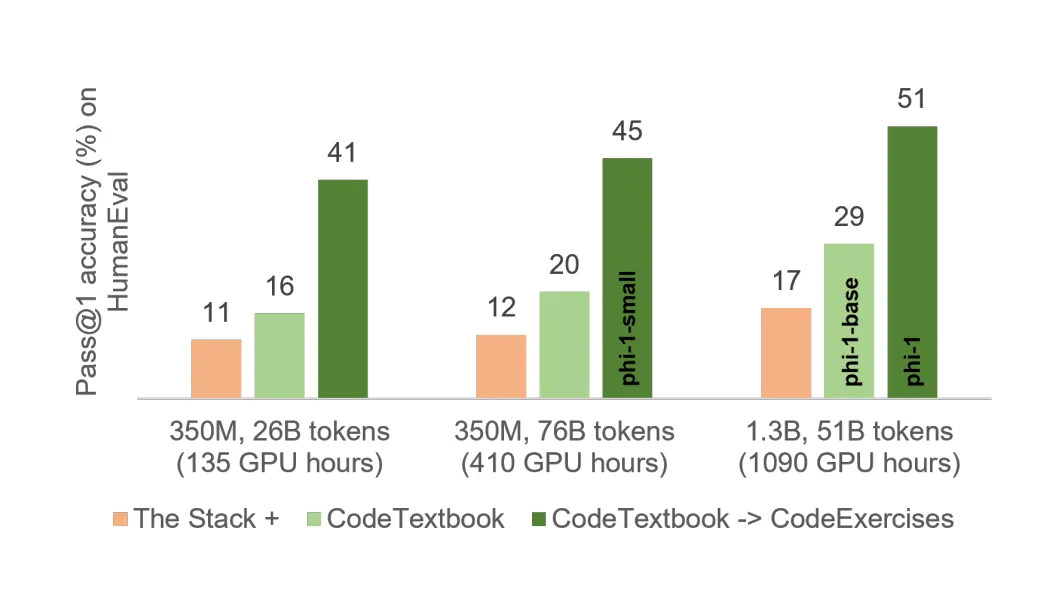
"Textbooks Are All You Need"
In their paper, "Textbooks Are All You Need," Gunasekar and team showcased the power of high-quality data. This paper pushes the envelope further and introduces the community to the Phi 1 model. They trained a compact 1.3B parameter model using meticulously filtered code, textbooks, and GPT-3.5-generated data. High-quality data greatly enhances the learning efficiency of language models, particularly for code, as it provides clear, self-contained, and instructive examples.
Fine-Tuning with Precision
Fine-tuning LLM models can yield outstanding results, but only when coupled with the utilization of high-quality, domain-specific data. The bulk of the effort is dedicated to data curation and ongoing refinement, guided by the LLM's performance.
The High Value of High-Quality Data in Enterprise AI
Data's Significance
In the realm of enterprise AI tasks, the importance of data cannot be overstated. However, when it comes to achieving remarkable performance, high-quality data holds the upper hand. Enterprise-specific open-source models, finely tuned on high-quality datasets, can achieve performance equivalent to GPT-4.
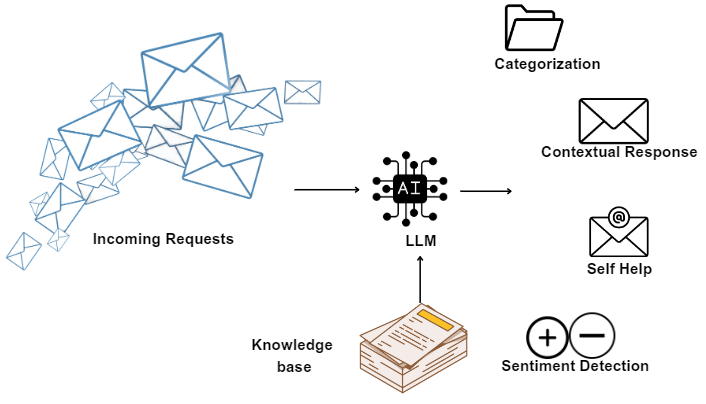
Enterprise High-Quality Data
The real challenge lies in securing high-quality data. Enterprises often possess valuable training data for specific use cases, such as a Q/A model built on their knowledgebase. For instance, customer support teams, by addressing customer inquiries, effectively curate substantial supervised training datasets.
Self-Instruction and Model-Generated Data
High-quality data can also be generated by LLMs themselves. The "self-instruct" method allows LLMs to create training data from their own responses. Alternatively, one LLM, like GPT-4, can generate a high-quality training dataset to fine-tune another LLM.
The Impact of High-Quality Data on LLaMA Model Performance
GPT-4 vs. GPT-3 Data Comparison
A comparison between two instruction-tuned LLaMA models revealed a significant performance difference. One was fine-tuned with data generated by GPT-4, while the other used data from GPT-3. The model fine-tuned with GPT-4-generated data excelled in the "Helpfulness" criterion, highlighting the value of high-quality LLM-generated data for fine-tuning.
Small High-Quality Datasets
Small, high-quality datasets prove highly effective for fine-tuning. Traditional human labeling techniques can also be employed to generate such datasets. To fine-tune a small LLM (100B) for a particular task, having a high-quality dataset is crucial.
Complexity of General-Purpose LLMs
Conversely, achieving powerful general-purpose LLMs often demands extensive data and training. It's uncertain whether merely increasing the dataset size will significantly enhance LLM reasoning.
Auto-Regressive LLMs and AGI
While auto-regressive LLMs serve various business and consumer purposes, it's unlikely that they can lead us to Artificial General Intelligence (AGI) solely through brute-force methods.