
How GPT4 and LLMs Transforming Scientific Discovery
28 November, 2023
Artificial intelligence is rapidly changing how we do research. Large language models (LLMs) like GPT-4 are revolutionizing scientific discovery by extracting insights from literature, assisting experiments, and generating hypotheses.
What are LLMs?
LLMs like GPT-4, PaLM, and Claude can understand language, answer questions, and even develop simple strategies through conversation. They work by analyzing vast amounts of text from the internet. Some key things that set them apart from other AI systems are their strong language understanding, ability to carry out multi-step reasoning, and capacity to generate text.
GPT-4's Impact on Key Fields
GPT-4 shows promise across many scientific areas like drug discovery, biology, chemistry and more. Bold highlights its top capabilities.
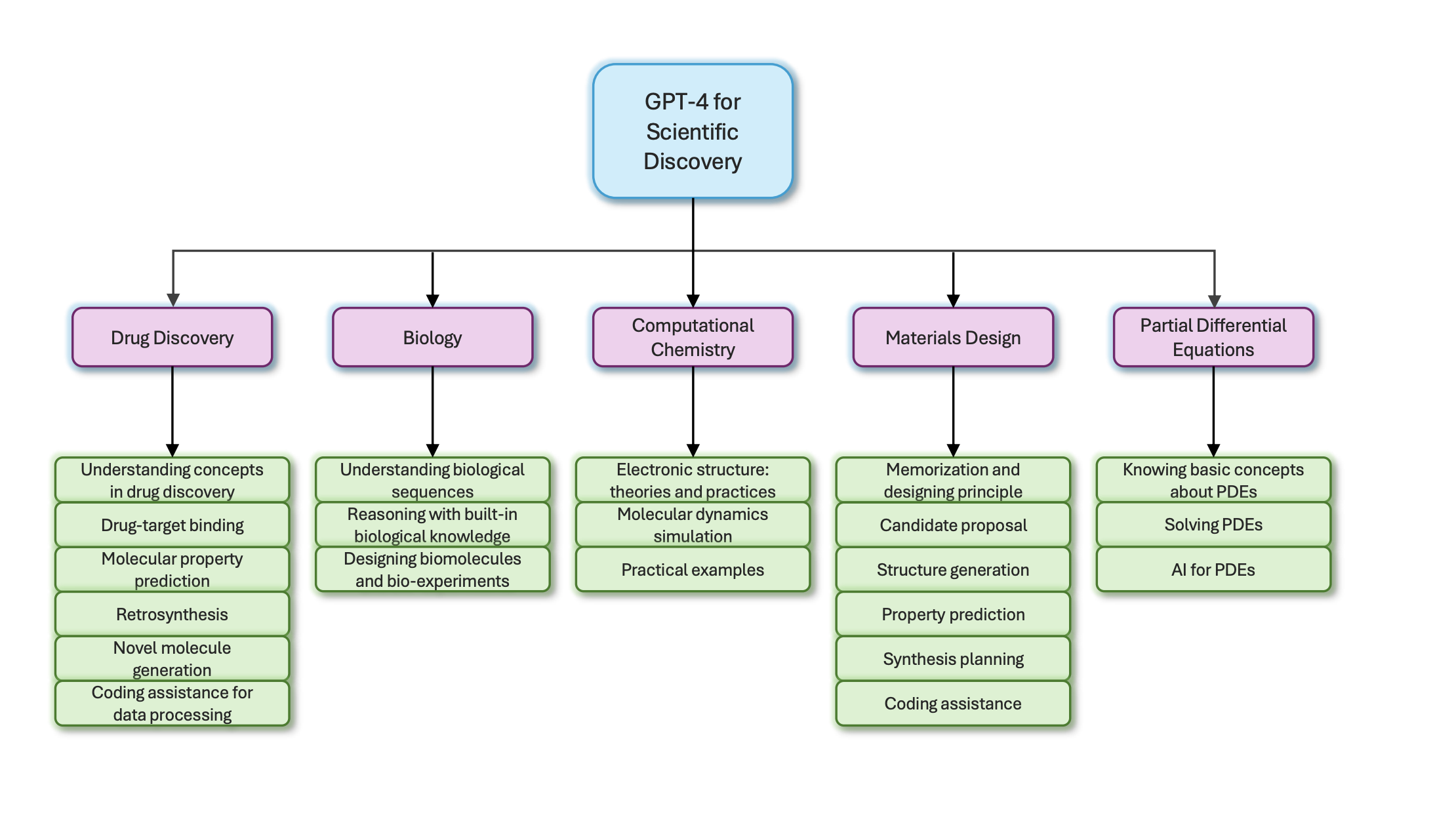
Drug Discovery
GPT-4 has an impressive grasp of drug discovery concepts. It helps with tasks like predicting drug interactions and retrosynthesis to determine synthesis routes. It does this by analyzing molecular structures and properties to find similar molecules in databases. However, it struggles with complex molecule representations like SMILES strings which can be non-intuitive for humans. Additionally, while it shows potential in qualitative analysis, improving its skills at precise calculations would enhance researchers’ trust in its quantitative predictions.

Biology
GPT-4 processes specialized files like genomes, proteomes, expression datasets and predicts properties of sequences, pathways and organism phenotypes. It reasons about biological mechanisms from observations of experimental results by drawing from its extensive biological knowledge graph. However, its performance on under-studied and rare entities needs improvement, as more training data is still required for those "long-tail" areas. Providing more context around tasks could also help researchers better evaluate its knowledge.
Computational Chemistry
GPT-4 demonstrates expertise across sub-domains like electronic structure methods and molecular dynamics simulations. It recommends suitable computational methods and software packages for tasks like density functional theory calculations based on molecule type and required accuracy. It can generate code snippets for popular chemistry programming languages to set up simulations. But generating precise atomic coordinates of complex organic molecules with many rotatable bonds remains challenging, as does working directly with raw coordinate/property data files without appropriate context.
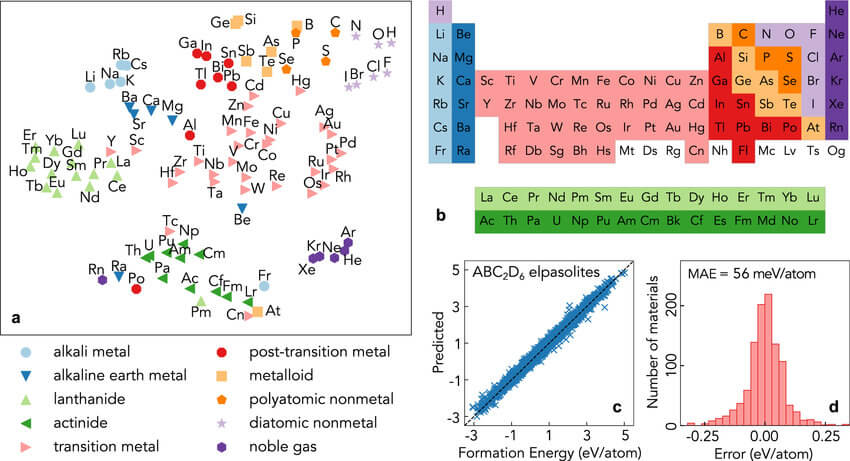
Chemistry captured by word embeddings
Word embeddings have shown success in representing chemical knowledge. A study projected the word embeddings of 100 chemical element names onto a 2D space using t-SNE. They found that chemically similar elements clustered together, resembling the periodic table structure. Position along the x-axis generally followed increasing atomic number from top right to bottom left. These embeddings were then used as features in a simple neural network to predict formation energies for around 10,000 ABC2D6 elpasolite compounds from their elemental compositions. With no extensive optimization, the mean absolute error of 0.056 eV per atom was substantially lower than previous methods using hand-crafted or automatically learned features. This demonstrates how word embeddings can effectively capture chemical relationships and properties without domain expertise, with potential for various structure-property prediction tasks.
Materials Design
GPT-4 aids materials design through literature search to discover structure-property relationships, principle suggestions to achieve target properties, and proposals of novel and feasible chemical compositions. It recommends appropriate experimental and computational analysis methods for characterization. While it shows potential in proposing conventional inorganic crystal structures, representing and suggesting more intricate organic or metal-organic frameworks still needs work. Generating accurate atomic positions for suggested structures also requires further refinement.
Evaluating Capabilities
Multiple aspects of GPT-4's we studied, including ability to access scientific literature, clarify concepts, analyze large datasets, develop theoretical models, guide methodology selection, make predictions for new scenarios, suggest experimental protocols, assist with code development, and generate novel hypotheses. It demonstrated proficiency in many areas through case studies, but still has room for growth in tasks requiring precise quantitative analysis or independent hypothesis formation without human input. Continued improvements in such areas will be important for boosting researchers' trust in relying on LLMs as collaborative tools.
Moving Research Forward
As LLMs evolve, they will transform scientific discovery in exciting ways. Researchers will be able to leverage LLMs' vast knowledge more efficiently through personalized research assistants that integrate specialized tools from various disciplines. LLMs showing early signs of general intelligence may even independently conceive new hypotheses by discovering unexpected connections across diverse topics. The future of science is highly collaborative, with humans and intelligent systems each contributing their unique strengths to push the boundaries of innovation.