
📗Importance of Vector Databases in Language Model Applications📚
28 August, 2023
In today's rapidly evolving technological landscape, language models like ChatGPT have become essential tools for a wide range of applications. From domain-specialized chatbots to automated Q&A systems, these models have shown remarkable capabilities in understanding and generating human-like text. However, these models do have limitations, especially when it comes to answering questions that require specific and up-to-date information. This is where vector databases come into play, bridging the gap between a model's general knowledge and domain-specific information.
Motivation for Vector Databases
Enterprise applications often require access to specialized information for improved productivity and efficiency. Whether it's a customer interaction history, codebase functionalities, or any other proprietary knowledge, having instant access to relevant information is invaluable. While ChatGPT can handle general knowledge queries, it falls short when faced with specialized and evolving information. For instance, it cannot provide answers about events or developments that occurred after its last training update. This limitation poses a challenge, particularly for businesses holding vast and continually updating repositories of specialized data.
Addressing Limitations through Prompting
The concept of "prompting" emerges as a solution to these limitations. Prompting involves providing a language model with specific information needed to answer a question. It leverages the model's conversational capabilities to generate well-formed responses. While the idea might sound straightforward, it represents a significant step towards enhancing a model's domain-specific knowledge. The process entails introducing the required context to the model within a token limit (e.g., 4096 tokens for GPT-3.5) and then asking the question, effectively guiding the model's response.
Embedding and The Vector Database Ecosystem
The vector database ecosystem is instrumental in building efficient and grounded query assistants with language models like ChatGPT. One notable framework is Langchain, which enables the integration of any text corpus for interaction with ChatGPT. The process relies on embeddings, which are vector representations of text, and a vector index for streamlined near-neighbor searches. The process can be divided into two main phases: pre-processing and querying.
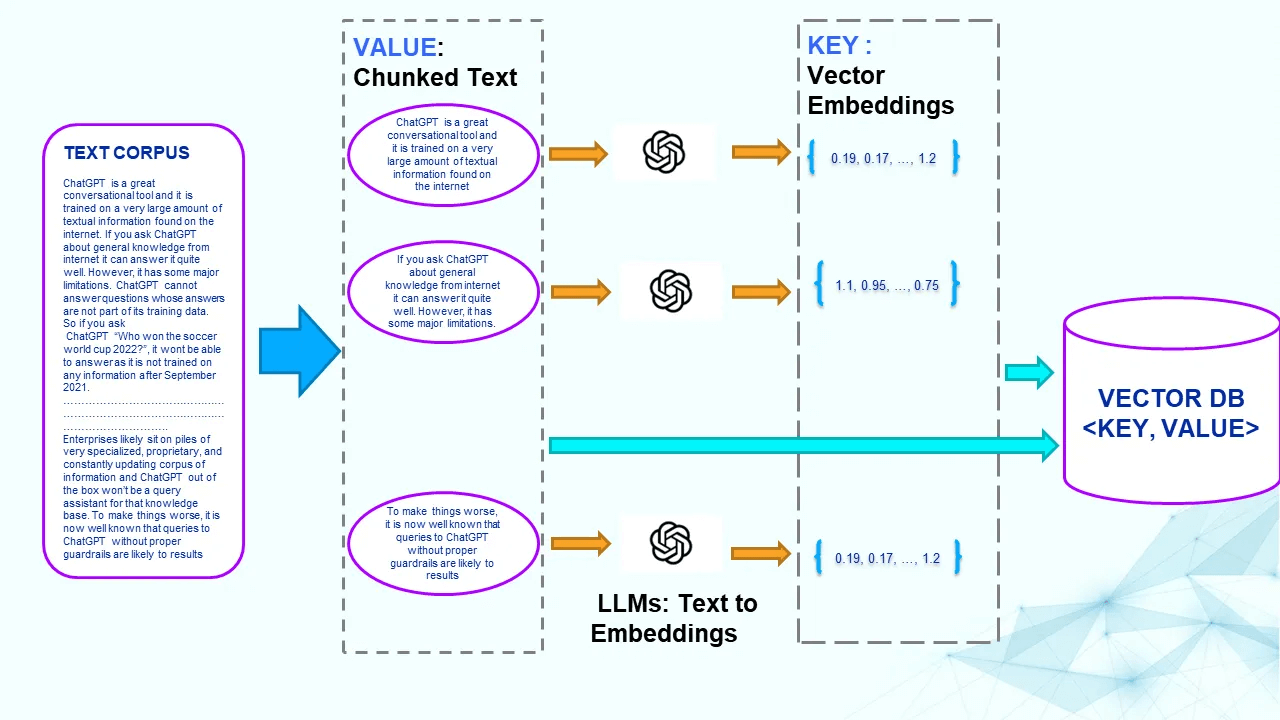
Pre-processing Step
In the pre-processing phase, raw text undergoes a series of steps to prepare it for efficient search and retrieval. Imagine a corpus of text documents intended for Q&A. This corpus is divided into smaller chunks, known as "chunks" or the chunking process. Each chunk is then passed through a trained language model (e.g., BERT or GPT) to generate an embedding, essentially a vector representation of the text. These pairs of text chunks and their corresponding embeddings are stored in a vector database, where the embedding serves as the key and the text chunk as the value. Importantly, vector databases offer efficient approximate near-neighbor (ANN) searches, allowing for effective retrieval based on vector similarity.
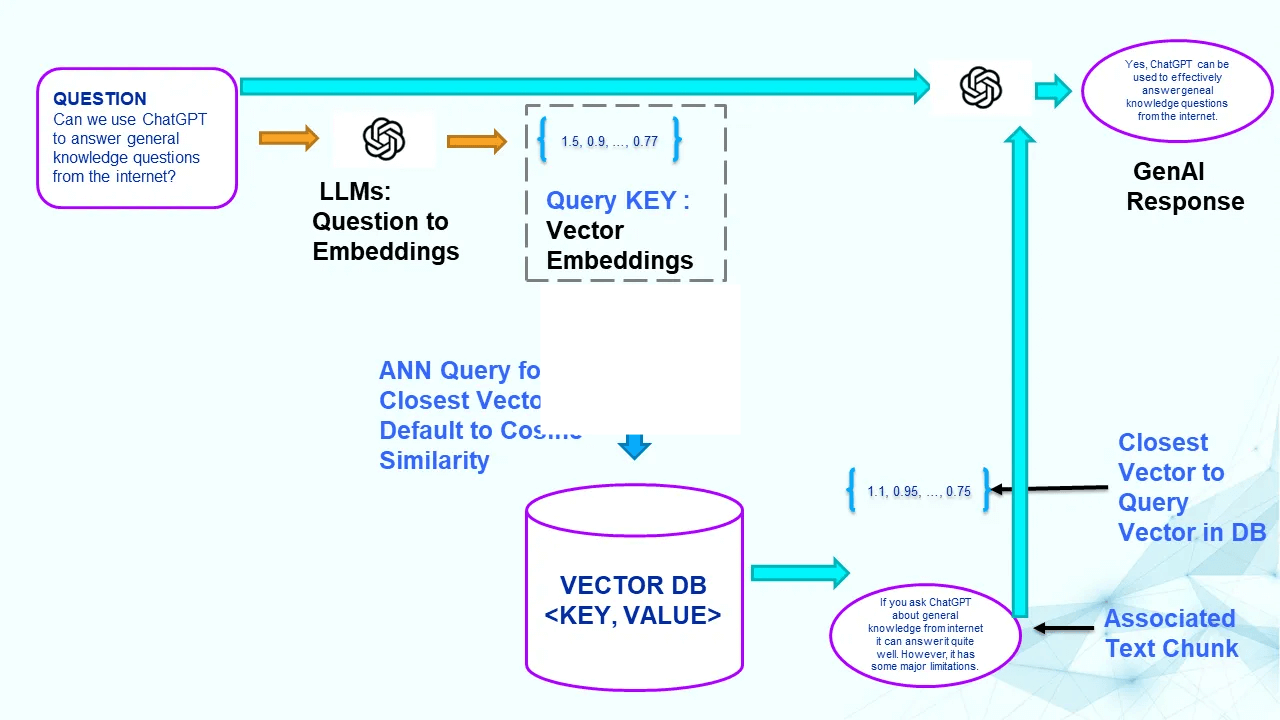
Query Phase: Embedding, ANN Search, and Generation
The query phase is where the vector database truly shines. User-typed questions trigger the search for the most relevant text content within the vector database. The following steps outline the process:
- Generating Query Embedding: The user's question is transformed into a vector embedding using the same language model employed for indexing the vector database. This embedding serves as the query key for the subsequent search. 🧠
- Approximate Near-Neighbor Search (ANN): An ANN search is performed in the vector database to find vectors closely resembling the query embedding. The similarity measure, often cosine similarity, determines the closeness. 🔍
- Identifying Relevant Information: The text chunks associated with the closest vectors are considered relevant to the query. These text chunks contain the information needed to answer the question. 📚
- Generation via Generative AI: The relevant information and the user's question are provided to a Generative AI model, such as ChatGPT, through a prompt. The model utilizes the provided context to generate a response that is informed by the retrieved information. 🤖
Conclusion
Vector databases play a crucial role in enhancing the capabilities of language models like ChatGPT for domain-specific applications. By enabling efficient retrieval of relevant information through embeddings and near-neighbor searches, these databases bridge the gap between a model's general knowledge and specialized data. As businesses continue to rely on AI-powered solutions, the integration of vector databases and prompting techniques paves the way for more accurate, informative, and valuable interactions between machines and humans. 🌐