
LLMs for Recommender Systems
10 August, 2023
What is a recommendation system?
Recommendation systems are everywhere. They're what help you find new music to listen to on Spotify, new movies to watch on Netflix, and new products to buy on Amazon. But what exactly are they?
In a nutshell, recommendation systems are a set of rules or algorithms that use data about your interests, behaviors, and preferences to make personalized recommendations. They work by finding other users who have similar interests to you and then recommending products or content that those users have enjoyed.
Recommendation systems are incredibly powerful. They can help you discover new things that you might never have found on your own. They can also help you save time and money by cutting out the need to browse through endless lists of products or content.

When to use a recommendation system?
For businesses, recommendation systems can be a major source of revenue. By recommending products or content that users are likely to be interested in, businesses can increase engagement and sales.
If you have a website or app with a lot of content or products, then you should seriously consider using a recommendation system. It can be a valuable tool for increasing engagement, improving conversion rates, and providing a better user experience.
Example of a recommendation system in action:
- A user is browsing through a carousel of products on an app. The carousel only shows 6 products at a time, but there are hundreds of products in the catalog.
- The recommendation system uses the user's past behavior and interests to suggest the 5 most relevant products to show in the carousel.
- If the user is interested in a product that is not currently in the carousel, they can swipe to see more products. The recommendation system will continue to suggest relevant products as the user swipes.
- If the user clicks on a product in the carousel, the recommendation system will learn more about their interests and use that information to suggest even more relevant products in the future.
- If the ideal product is just outside the displayed range, say at position 8, and the user doesn't swipe further, you miss out on a valuable conversion opportunity.
Types of data used in recommendation systems
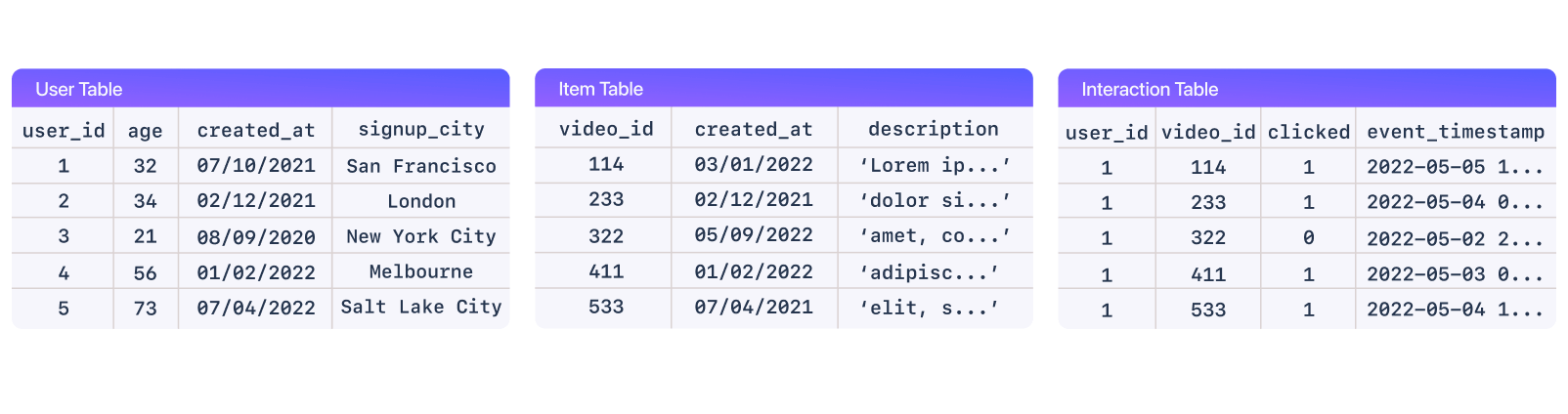
One way we can categorize data for recommendation systems is using these three categories: users, items and interactions.

- Users This data includes information about the users, such as their age, gender, location, interests, and purchase history.
- Items This data includes information about the items, such as their title, description, genre, and rating.
- Interactions This data includes information about how users have interacted with items, such as views, clicks, ratings, purchases, likes, dislikes, loves, and any other positive or negative event that you track.
The interactions data is the most important because it tells the recommendation system how users feel about specific items. This data allows the system to understand the relationship between users and items, and to make more accurate recommendations.
For example, if a user has clicked on a lot of products related to fashion, the recommendation system will know that the user is interested in fashion. The system can then recommend other fashion products to the user.
Explicit and Implicit Interactions in Recommendation Systems
Explicit interactions are direct, intentional actions taken by users to express their preferences. This includes things like ratings, reviews, and likes. Explicit interactions provide strong, unambiguous feedback about user preferences, making it easier for recommendation systems to learn from them.
For example, if a user rates a movie 5 stars, it's a pretty clear signal that they enjoyed the movie. This information can be used by a recommendation system to recommend other movies that the user might also enjoy.
Implicit interactions are indirect actions taken by users. This includes things like browsing history, clicks, time spent on an item, and purchase history. Implicit interactions are often more abundant than explicit interactions, but they can be harder to interpret since they don't always indicate a clear preference.
For example, if a user clicks on a product on an e-commerce website, it doesn't necessarily mean that they want to buy the product. They might have just been curious about the product or they might have been comparing it to other products.
Despite the challenges, implicit interactions can be valuable data for recommendation systems. By tracking implicit interactions over time, recommendation systems can learn about user preferences and make more accurate recommendations.
Netflix and TikTok are two examples of companies that use both explicit and implicit interactions to power their recommendation systems. Netflix uses explicit interactions like ratings and reviews to make recommendations, but they also use implicit interactions like browsing history and watch time. This helps Netflix to make more personalized recommendations for each user.
TikTok, on the other hand, relies more heavily on implicit interactions. The For You Page on TikTok only shows a single video at a time, and users can only interact with the video by liking, commenting, or sharing it. This means that TikTok has a lot of data about how users interact with videos, which they can use to make personalized recommendations.
Ultimately, the best way to use explicit and implicit interactions in a recommendation system depends on the specific application. For example, if you're recommending products to users, you might want to rely more on explicit interactions like ratings and reviews. But if you're recommending videos to users, you might want to rely more on implicit interactions like watch time and likes.
The key is to use a combination of explicit and implicit interactions to create a more personalized and accurate recommendation experience for users.

The secret to LLMs success
Large language models (LLMs) are revolutionizing the way we build recommendation systems. Unlike traditional recommendation systems, which rely on keywords and metadata, LLMs can understand the entire text of an article or video to make recommendations that are not only relevant but also aligned with the user's interests and preferences.
Here's how it works: LLMs are trained on massive datasets of text and code. This allows them to learn the statistical relationships between words and phrases. When a user interacts with an LLM-powered recommendation system, the system can analyze the user's past behavior and interests, as well as the text of the items that the user is interested in. This information is then used to generate a personalized list of recommendations.
LLMs are also capable of learning from user feedback. If a user clicks on a link that was recommended by an LLM, the system will take note and use that information to improve its future recommendations. This feedback loop allows LLMs to continuously refine their recommendations and provide an even better user experience over time.
As LLMs continue to develop, they will become even more powerful and versatile tools for building recommendation systems. This will lead to a new era of personalized recommendations that are more relevant, engaging, and helpful than ever before.
How can recommender systems benefit from Large Language Models?
The surge in recommendation systems parallels the evolution of online services, responding to the challenge of user information overload and the pursuit of higher data quality. A fundamental objective across diverse application tasks, such as top-N or sequential recommendations, is prevalent in deep learning-based recommender systems: gauging a user's affinity for potential items and orchestrating them into a prioritized user-facing list.
LLMs can be used to improve recommendation systems in a number of ways
- They can provide more accurate recommendations. LLMs can understand the text of items and the user's past behavior in a way that traditional recommendation systems cannot. This allows them to make more accurate recommendations that are more likely to be relevant to the user.
- They can provide more personalized recommendations. LLMs can understand the context in which recommendations are made. This allows them to provide recommendations that are more tailored to the user's current needs and interests.
- They can be used to generate new items. LLMs can be used to generate new text, which can be used to create new items for recommendation. This can help recommendation systems to stay up-to-date with the latest trends and interests.
Simultaneously, substantial strides in natural language processing (NLP) have been showcased by large language models (LLMs). These models exhibit capabilities like contextual reasoning and rapid learning within a specific context, alongside a comprehensive repository of wide-ranging information encoded within their pre-trained model parameters.
Where to Incorporate LLMs?
So, where can we effectively integrate LLMs? While we've already discussed their potential, the array of possibilities demands a consideration of their placement within the pipeline. The figure below illustrates the numerous approaches developed in the past two years with the aim of integrating large language models to enhance existing recommendation system pipelines. To comprehend their nuances, I'll briefly elucidate each sector:
LLM for Feature Engineering
Here, LLMs can augment the original data input by generating additional textual features. This approach has shown promise with tabular data and has been extended to align out-of-domain datasets for shared tasks. LLMs can also be used for generating tags and modeling user interests.
LLM as Feature Encoder
In traditional recommendation systems, data is often transformed using one-hot encoding and an embedding layer is added for dense embeddings. LLMs can enhance this process by providing better representations through extracted semantic information applied to embeddings. This can lead to improved cross-domain recommendations where feature pools might not be shared. For example, UNBERT enhances news recommendations using BERT for feature encoding, while ZESREC employs BERT to convert item descriptions into continuous zero-shot representations.
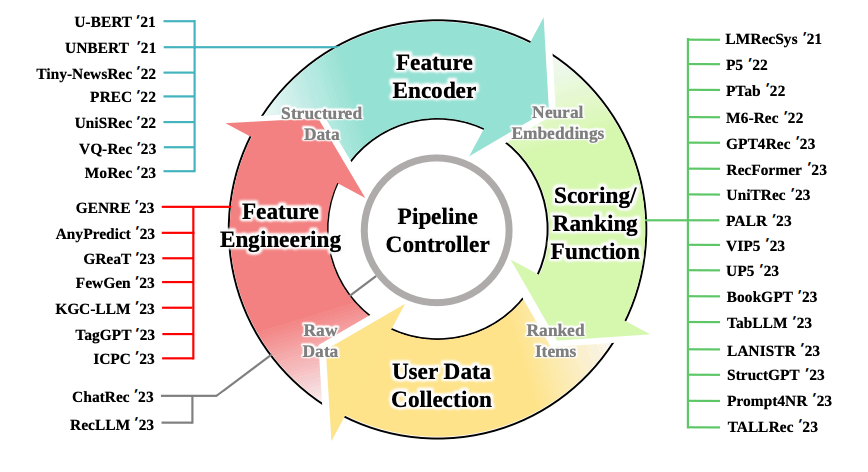
LLM for Scoring/Ranking
A prevalent approach involves using LLMs to rank items based on their relevance. Some methods incorporate a pipeline where the LLM's output feeds into a projection layer to calculate scores for regression or classification tasks. Recent research proposes using LLMs to directly deliver the score. For instance, TALLRec uses LLMs as decoders to answer binary questions appended to prompts, while others predict scores textually and format them with careful prompting. LLMs can also be used for direct item generation, similar to the approach in the previous blog post. These strategies can also be hybridized and combined.
LLM as a Pipeline Controller
This approach is founded on the idea that LLMs possess emergent properties, such as contextual learning and logical reasoning, which smaller models lack. However, it's worth noting that some researchers dispute these claims, attributing these properties to statistical methods that bias evaluation rather than inherent scaling properties of AI models. Some researchers have proposed comprehensive frameworks that leverage LLMs to manage dialogues, comprehend user preferences, organize ranking stages, and simulate user interactions.
It's evident that the user data collection aspect is missing. Not much exploration has been done regarding LLM potential in this domain. LLMs can be used to filter biased or hateful data, select optimal representations, or extract meaningful information from a deluge of input. They can also serve as customer experience collectors in surveys and fulfill various other roles.
Pretraining Foundation Language Model on Recommendation Tasks
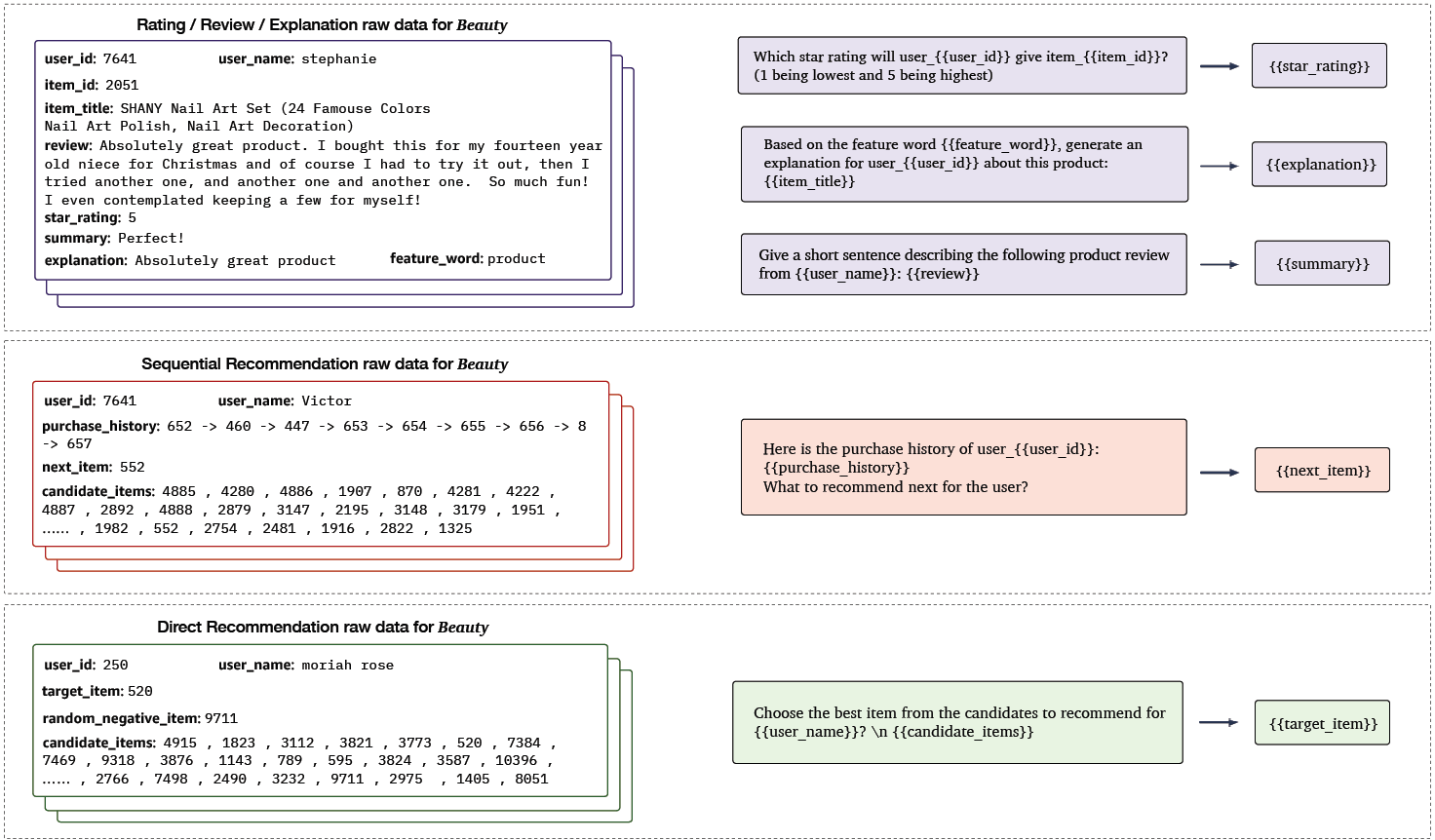
In their groundbreaking work titled "Pretrain, Personalized Prompt & Predict Paradigm (P5)," Geng and colleagues introduced a novel methodology for constructing advanced recommender systems. This innovative framework amalgamates five distinct recommendation tasks, namely Sequential Recommendation, Rating Prediction, Explanation Generation, Review Summarization, and Direct Recommendation, within a unified text-to-text paradigm. During the pretraining phase, these diverse tasks are seamlessly integrated through a shared language modeling objective.
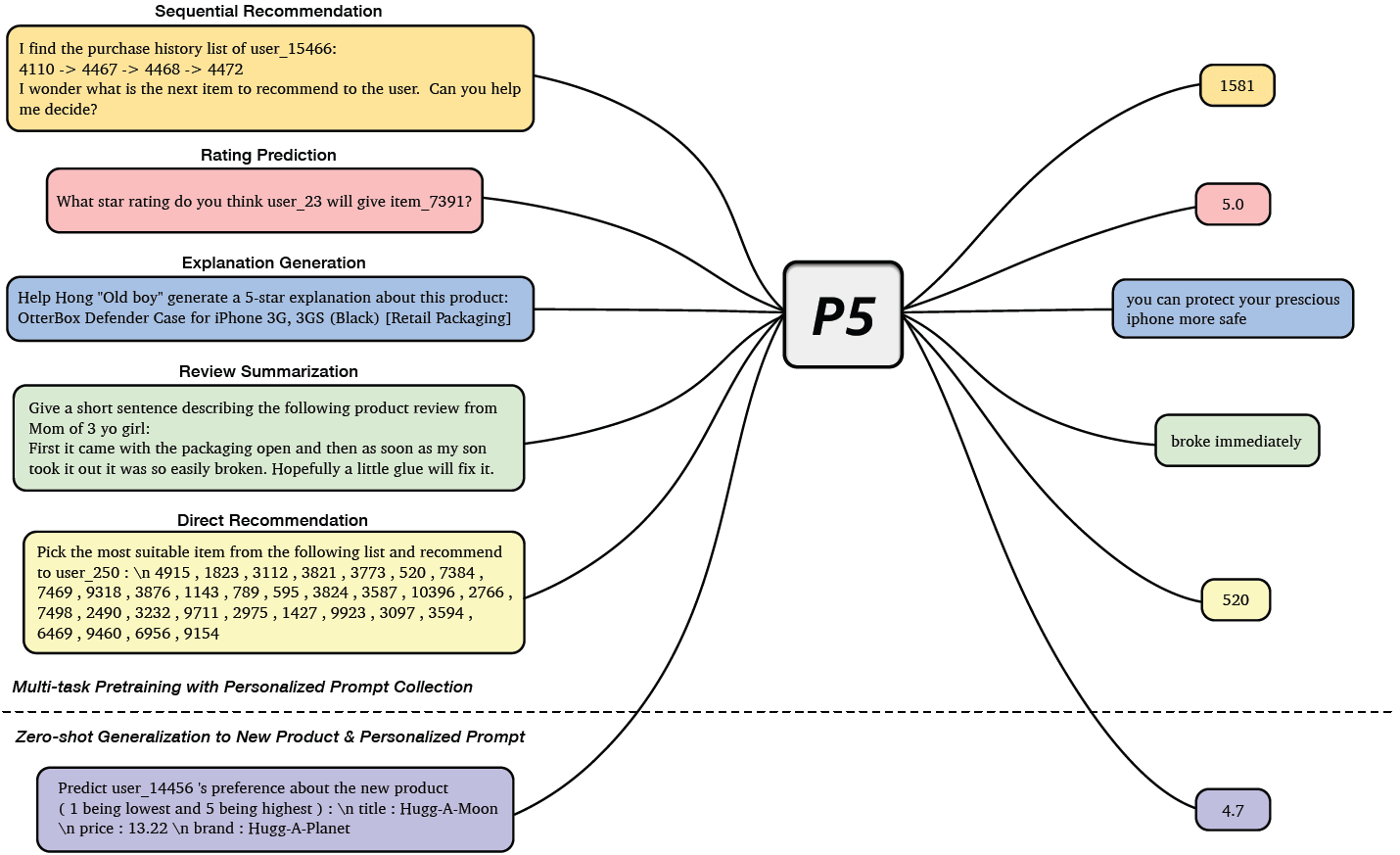
In this comprehensive approach, all available data sources such as user profiles, item attributes, user reviews, and user-item interactions are transformed into coherent natural language sequences. This process capitalizes on the inherent richness of information within a multitask learning environment, enabling P5 to adeptly capture the semantic intricacies necessary for crafting personalized recommendations.
Illustrated in the visual representation below, P5 undertakes the joint mastery of these interconnected recommendation tasks, employing a cohesive sequence-to-sequence framework presented in prompt-based natural language structure. The model's input features are skillfully integrated using adaptive personalized prompt templates, which serve as dynamic conduits for channeling task-specific information. P5 treats each personalized task as a conditional text generation challenge, effectively addressing them through a meticulously designed encoder-decoder Transformer model. This model is preloaded with instruction-based prompts, skillfully crafted to encompass user and item attributes. These personalized prompts are thoughtfully categorized into three distinctive templates, as exemplified in the accompanying figure, which showcases instances from the beauty products category drawn from an Amazon dataset.
Why should you use LLMs for building recommendation systems?
There are several key aspects of Large Language Models (LLMs) that make them an excellent option for constructing recommendation systems.
- By including user behavior data as part of the task descriptions, also known as prompts, the knowledge stored within LLM parameters can be harnessed to create personalized recommendations. The reasoning capability of LLMs enables them to deduce user interests from the context provided by these prompts.
- Research into zero and few-shot domain adaptations for LLMs has demonstrated their effectiveness in seamlessly adapting to different domains. This adaptability empowers startups and large enterprises to enter new domains and establish recommendation applications even when working with limited domain-specific data.
- Commonly, large-scale recommender systems are built as multi-step cascade pipelines. Utilizing a single LLM framework for recommendations can streamline the incorporation of shared improvements, such as bias reduction, that are often individually fine-tuned at each step. This approach can also be environmentally friendly by avoiding the need to train separate models for each downstream task, thereby reducing the carbon footprint.
- In most workflows, diverse recommendation tasks draw from a common pool of user-item interactions and possess overlapping contextual features. This commonality suggests that these tasks can significantly benefit from unified frameworks that standardize input representations and enable collaborative learning. Such a learned model is likely to generalize well to new tasks.
- LLMs are interactive in nature, making them valuable for explaining how recommendations are generated. Additionally, the feedback mechanism inherent to LLMs contributes to an enhanced overall user experience, facilitating continuous improvements in the recommendation process.
Conclusions and the Future of LLMs in Recommendation Systems
Large language models (LLMs) have emerged as a powerful tool for recommendation systems, thanks to their ability to understand the nuances of natural language and to learn from large amounts of data. LLMs can be used to generate personalized recommendations, to provide recommendations for new items, and to improve the accuracy of recommendations.
In the future, LLMs are likely to play an even greater role in recommendation systems. As LLMs continue to grow in size and complexity, they will be able to learn more about user preferences and to generate more accurate recommendations. Additionally, LLMs are being used to develop new types of recommendation systems, such as conversational recommender systems that can interact with users in natural language.
The use of LLMs in recommendation systems is still in its early stages, but it has the potential to revolutionize the way that recommendations are made. LLMs can help to improve the accuracy, personalization, and relevance of recommendations, which can lead to a better user experience and increased sales.
As the field of recommendation systems continues to evolve, LLMs will likely continue to be a focal point of research and development. Their capabilities in understanding user behavior and preferences, as well as their ability to generate natural language recommendations, make them a powerful tool in creating more effective and engaging recommendation systems.
With ongoing advancements in AI and natural language processing, we can anticipate more innovative uses of LLMs in recommendation systems, and their integration into various industries to create more tailored and impactful experiences for users.
So, whether you're a content provider, an e-commerce platform, or any other business seeking to enhance user engagement and satisfaction, consider harnessing the power of LLMs to elevate your recommendation systems to new heights.
Embrace the future of personalized recommendations powered by LLMs and embark on a journey of transforming how users discover, engage with, and enjoy content and products.