
Sampling from Data Distributions In Machine Learning and AI
18 October, 2023
Your data distribution is your ML model's DNA, encoding the patterns vital for its training, much like DNA holds the blueprint of life.
The Heart of ML and AI
Every ML and AI model relies on a dataset with specific data point arrangements in a multi-dimensional space. A robust data distribution mirrors real-world scenarios, and this is critical.
Why a Balanced Distribution Matters
A robust distribution encompasses diverse categories and captures data variability effectively. This shields the model from noise, outliers, or anomalies.
Data Understanding is Key
Data scientists begin by comprehending data distribution. The better you know your data's shape, the easier it is to address issues like imbalances and biases. Additionally, this understanding aids in selecting the right algorithm and configuration for the task.
Sampling: The Key to Effective Data Modeling
Datasets themselves are subsets, or "samples," of real-world measurements we aim to model. For predictive models and supervised learning, algorithms work with a portion of recorded observations.
Millions to Billions of Choices
With millions or even billions of observations available, data scientists must carefully choose a representative subset.
Crucial Role of Sampling
Sampling is a vital part of preparing data for machine learning models. Different sampling techniques address distinct requirements and situations.
Popular Sampling Methods in Data Science
Here are the most widely used sampling techniques in data science today.
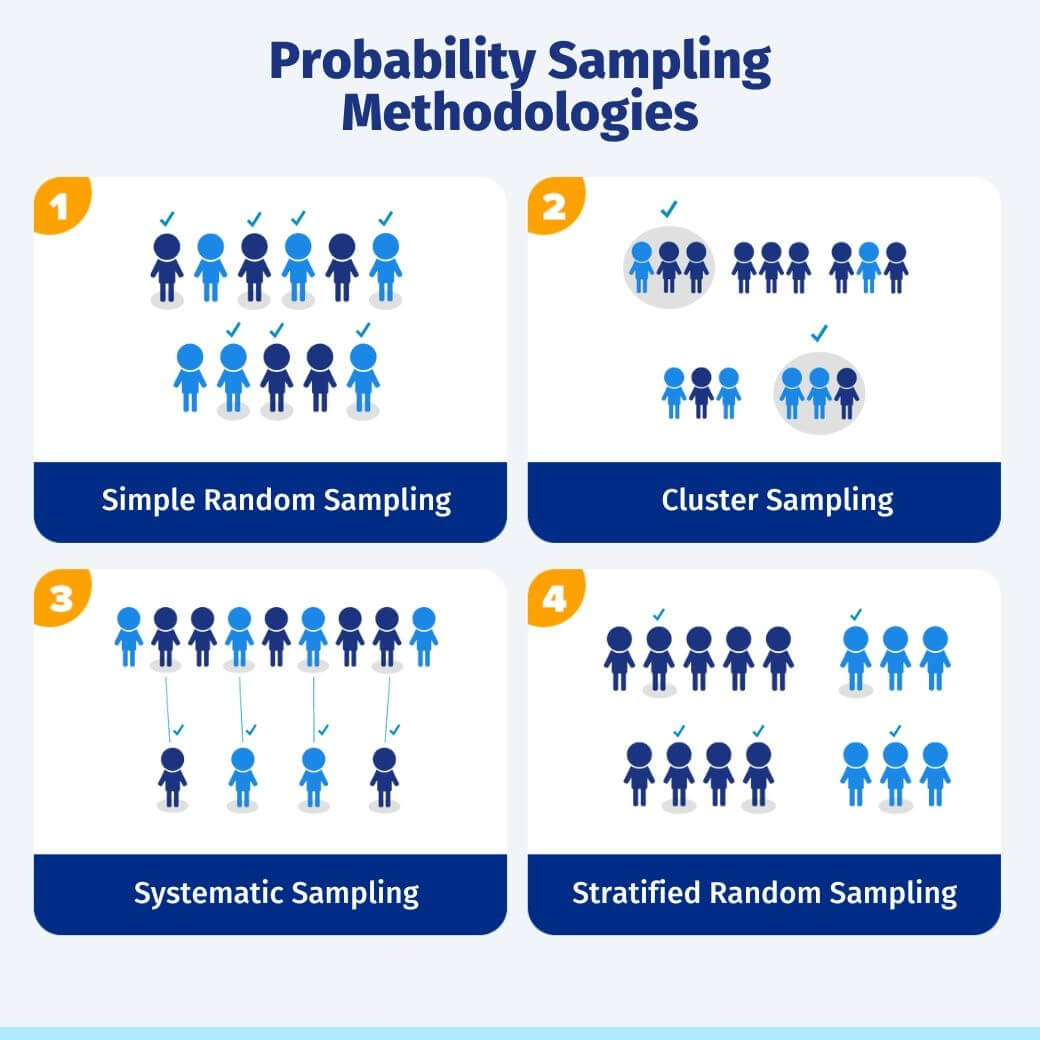
1. Random Sampling
Every data point has an equal chance of selection, ensuring representativeness and minimizing selection bias. Crucial for unbiased population parameter estimations.
2. Cluster Sampling
Divides the population into clusters, randomly selects clusters, and analyzes all data points within those clusters. Efficient for large datasets or geographically dispersed populations, though it may introduce inter-cluster correlation bias.
3. Systematic Sampling
Data points are chosen at regular intervals to cover the dataset evenly. It's computationally efficient but requires a random data point distribution to prevent periodic biases.
4. Stratified Sampling
Divides the dataset into homogenous subgroups (strata) and selects data points within each stratum randomly. Ensures proportional representation and reduces sampling error, ideal when there are variations among subgroups.
Addressing Class Imbalance in Binary Classification Models
Class imbalance is a common challenge in real-world binary classification models, where one class significantly outnumbers the other. For instance, fraud detection datasets typically have more "not fraud" examples compared to "fraud" instances.
Class Imbalance Solutions
Two techniques combat class imbalance: oversampling and undersampling. Oversampling increases the rare class instances, while undersampling reduces the majority class instances, effectively mitigating bias in classification tasks.
SMOTE
SMOTE (Synthetic Minority Over-sampling Technique) is a well-known method. It creates synthetic samples from the minority class, promoting diversity and enhancing classifier performance, instead of merely duplicating instances.
Leveraging LLMs for Synthetic Data
Surprisingly, you can employ Large Language Models (LLMs) like GPT-4 to generate synthetic examples of a specific class. By providing a set of examples and requesting variations, especially for text-heavy content, LLMs can produce high-quality data.
Data Science Best Practices
These sampling techniques are core to data science. They guarantee representativeness, combat class imbalances, and streamline large or intricate datasets, ultimately elevating machine learning model performance and result interpretability.