
The Human Factor Why Intelligence and Intuition Remain Crucial in Financial Machine Learning
5 September, 2024
Since the release of ChatGPT in November 2022, AI has dominated headlines, generating both excitement and debate. While large language models (LLMs) have showcased their transformative potential, they are not a one-size-fits-all solution to every AI challenge. Financial machine learning is one such area where more nuanced techniques—often driven by human intelligence—still hold sway.
The capabilities of machine learning models are ultimately bound by the skills, experience, and intuition of the humans who create and guide them. No matter how powerful the algorithm, without expert human oversight, the model risks misinterpreting data or falling short in real-world applications.
In this article, I aim to provide a comprehensive perspective on the interplay between human and artificial intelligence, particularly within finance. While AI has made significant inroads, there are inherent limitations that necessitate human intuition, especially in complex environments like financial markets. Knowing how to blend AI's capabilities with human insight will be key for firms wanting to excel in an era dominated by AI-driven advancements.
Data Limitations
A core challenge in machine learning is the selection and utilization of the right data. Even the most advanced algorithms cannot function effectively without well-curated, relevant data. Frequently, issues arise from either the quality of data or the way the problem is framed by researchers. In these scenarios, human intuition becomes essential, guiding decisions on whether the data available can support the development of a reliable machine learning model. The aim is not only to create systems that analyze data but also to make informed, actionable decisions on behalf of humans.
Yet, sometimes, even vast amounts of data are insufficient to solve the problem. The limitations of data in financial markets are significant and include issues like:
Data Quality Problem
Consider the potential for fine-tuning a large language model like GPT-4 on stock market data. In theory, supplying the model with a corpus of financial documents paired with stock returns could help it learn statistical relationships between these variables. However, practical constraints make this approach far less promising.
Training LLMs to predict long-term stock returns is particularly difficult, as we highlighted in "Deep Learning in Investing: Opportunity in Unstructured Data" (July 2020). The main problem is not just the complexity of the task but the inherent limitations in financial market data.
Financial market data suffers from three primary limitations: it is small, noisy, and non-stationary.
-
Small Data
Unlike natural language models, which are trained on massive datasets, financial data is relatively limited. Llama 3, for instance, was trained on 15 trillion tokens, whereas long-term investors have access to fewer than 100,000 distinct training observations—3,000 stocks over 30 years. This small dataset limits the learning potential of models in a field as complex as stock market predictions.
-
Noisy Data
Financial markets are inherently noisy, with even the best investors achieving hit rates only slightly above 50% when predicting stock returns. In comparison, LLMs often exceed 90% accuracy in natural language and vision tasks. The noise in financial data makes it harder to train models, as each data point holds less informational value.
-
Non-Stationary Data
Perhaps the most significant issue is the non-stationary nature of financial markets. As markets evolve, predictive features that once worked are quickly arbitraged away, rendering models trained on historical data obsolete. Unlike the relatively stable natural language data used in training LLMs, financial data is in constant flux, making it challenging to generalize from past trends.
In the long-term, brute-force approaches that rely on training AI with vast amounts of historical stock data are unlikely to yield breakthrough results. Instead, progress will depend on developing AI models that can reason from first principles, adapting to market shifts in real time—a challenge current models are improving on, but are not yet fully capable of.

There Is No Signal in the Data You Have
Lack of signal in data is a common obstacle in machine learning. This absence can arise from various factors, such as the inability of the dataset to capture root causes or early warning symptoms, as observed in certain domains. For example, in an attempt to predict crop loss in Malawi using satellite imagery and ground surveys, researchers found that the country’s relatively stable weather and small size led to insufficient variability in the data, making it difficult to create a robust predictive model. This issue is not unique to agriculture and occurs in many sectors where signals are weak or subtle.
Even when symptoms or early indicators are available, they may lack enough variability to be meaningful. The variability, or "spread" in the data, is often crucial for machine learning models to learn from and make predictions. For instance, predicting complex outcomes such as stock market movements or disease outbreaks requires not only abundant data but also high variability in the features used. When the signal is too weak, the model either needs a much larger dataset or fewer features to avoid the curse of dimensionality, which refers to the exponential growth in computational difficulty as the number of features increases. This relationship between data, features, and signal strength is a delicate balancing act in machine learning.
Causality vs. Correlation
A critical issue in applying machine learning to real-world problems is understanding the difference between correlation and causation. Many machine learning models, especially those in finance, operate under the assumption that the relationships they find between features and outcomes are stable. However, this assumption breaks down when the action taken based on the prediction influences the outcome. This is often the case in high-stakes financial decisions.
For example, predicting earnings surprises based on historical data may be relatively straightforward because the action of making a prediction has no direct impact on the earnings report itself. On the other hand, predicting the optimal trade execution strategy is far more complex, because a large transaction might directly influence the price of a financial asset. Such cases require a more nuanced approach that goes beyond traditional prediction techniques, incorporating causal models that can account for the effects of actions. Techniques like causal inference, A/B testing, and randomized control trials become invaluable in these scenarios as they provide ways to isolate and measure the impact of specific actions.
Predicting effects accurately in these types of environments may or may not be feasible, but understanding the causal dynamics at play is essential for avoiding misleading predictions.
Depth of Solution Creativity
While the challenges in machine learning are significant, they do not signal a dead-end for innovation. Human intuition, with its ability to think outside the bounds of structured data, can often find creative solutions where machine learning models fall short. For example, when data signals are weak or nonexistent, a skilled data scientist might recognize that the model is chasing noise rather than meaningful trends.
In supervised learning, one of the advantages over other machine learning approaches is the ability to objectively evaluate model performance against a known ground truth. This makes failure obvious and, thus, provides clear feedback to refine the model. Even large language models (LLMs) like GPT-4 are trained with a form of supervised learning, as they aim to predict the next word in a sequence. This focus on predicting ground truth allows for clear progress, but in some cases, ground truth is not easy to define.
Take the example of a company trying to estimate the maximum sales potential, or “customer wallet,” for its salesforce. This quantity is almost never explicitly known. However, by reframing the problem, one can create a supervised learning task. Instead of predicting the total wallet size, the task can be changed to estimating a “realistic wallet,” or the maximum amount a customer could spend given their current engagement with the company. This transforms the problem into one where a model can be trained to estimate an upper revenue limit using tools like quantile regression, which focuses on predicting high-percentile outcomes rather than average outcomes.
Causal Modeling and Quantile Regression
The reframing of machine learning problems is a powerful technique. In the salesforce example, instead of asking for an impossible-to-know ground truth (the exact total wallet size), a more tractable question is posed: What is the realistic upper-bound revenue potential of a customer? Here, quantile regression offers a solution. Rather than minimizing the sum of squared errors (which assumes an average outcome is of interest), quantile regression minimizes weighted absolute errors, allowing the model to predict a specific percentile—such as the 90th percentile of customer revenue. This adjustment in approach provides a robust solution even in cases where the ground truth is inherently difficult to define.
In tree-based models, instead of predicting the average revenue within each leaf, the model could predict a near-maximum value, offering a better fit for revenue forecasting where the aim is to capture higher-end performance.
This shift in approach demonstrates the flexibility and creativity required in machine learning when faced with ambiguous or incomplete data. It also highlights the indispensable role of human insight in guiding model development and applying the right techniques to extract meaningful predictions.
By blending human intuition with machine learning techniques like causal modeling and quantile regression, we can navigate the limitations of data, identify creative solutions, and ensure models are not just mathematically sound but also relevant and actionable in real-world applications.
Setting the Right Direction with Transfer Learning
In recent years, transfer learning has emerged as a transformative technique within machine learning, particularly in the context of deep learning. Transfer learning refers to the practice of storing knowledge gained from solving one problem and applying it to another, potentially unrelated problem. In finance, this has been an exciting development, particularly when data for specific tasks is scarce or expensive to acquire.
Imagine building a sentiment analysis model for stock price forecasting. Normally, this would require vast amounts of high-quality financial news data, analyst reports, or other text sources related to financial markets. However, a model pre-trained on general news sentiment can be fine-tuned using smaller, sector-specific datasets (such as technology or pharmaceuticals). By applying transfer learning, the model leverages the broader patterns it learned from general news and transfers that knowledge to financial data, achieving a higher degree of accuracy in predicting stock price movements based on news sentiment.
Transfer learning in finance also extends beyond sentiment analysis. It can be applied to risk management models, for instance, where a model pre-trained on global market volatility can be adapted to forecast volatility in emerging markets, where data is historically more limited.
| Task | Pre-trained Model | Transfer Target | Performance Gain (%) |
|---|---|---|---|
| Stock Price Sentiment | General News Sentiment Model | Tech Sector News Data | +12% |
| Risk Forecasting | Global Market Volatility | Emerging Market Volatility | +8% |
| Portfolio Optimization | U.S. Stock Data | European Market Stocks | +10% |
As this table illustrates, the power of transfer learning lies in its ability to save time, resources, and computational effort while providing superior outcomes. This approach allows financial institutions to work more efficiently, enhancing decision-making processes.
Bias in Model Predictions
Machine learning models are highly effective at making predictions, but one of their vulnerabilities is their tendency to favor “easy” predictions. In finance, this can lead to biases, especially when the model's predictions seem unusually good.
Consider a quantitative model designed to predict stock returns. A slight improvement over random chance in forecasting returns can yield a highly successful trading strategy. However, when the model achieves far greater accuracy than expected, it’s important to exercise caution. Exceptional performance could be a red flag, indicating the presence of biases or even data leakage—where information from the future unintentionally slips into the model, artificially inflating its performance.
Hypothesis: Is the Model Too Good to Be True?
Let's hypothesize a model predicting asset returns with 85% accuracy. For a domain as inherently noisy and unpredictable as the stock market, such a high success rate would warrant suspicion. Even a model with 55% accuracy, if consistent, can outperform benchmarks like the S&P 500. Anything beyond this should be met with scrutiny, including rigorous back-testing and cross-validation across different time periods and market conditions.
| Prediction Accuracy (%) | Expected Annual Return (%) | Notes |
|---|---|---|
| 50% | 8% | Random, equivalent to index performance |
| 55% | 12% | Slight edge, highly profitable in the long run |
| 85% | 25% | Suspiciously high, likely due to data leakage |
This underscores the importance of human intuition in detecting anomalies. In finance, models that perform too well should be challenged, as it is far more likely that the model is inadvertently fitting noise in the data rather than discovering genuine market signals.

Detecting Biases
Human intuition plays an irreplaceable role in identifying biases. For instance, a model tasked with predicting which customers are likely to default on loans could inadvertently favor predictions based on variables that are easy to quantify, such as the frequency of late payments. However, these factors may not capture the full picture, such as the customer’s sudden increase in wealth or life changes that could impact future behavior. Without a human-in-the-loop, models tend to miss these subtleties.
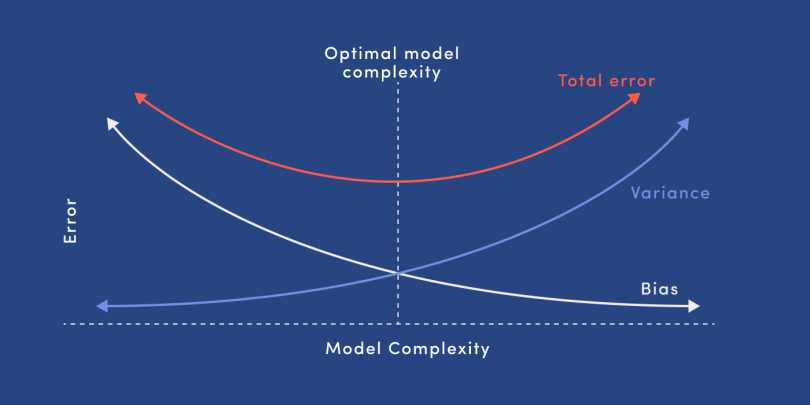
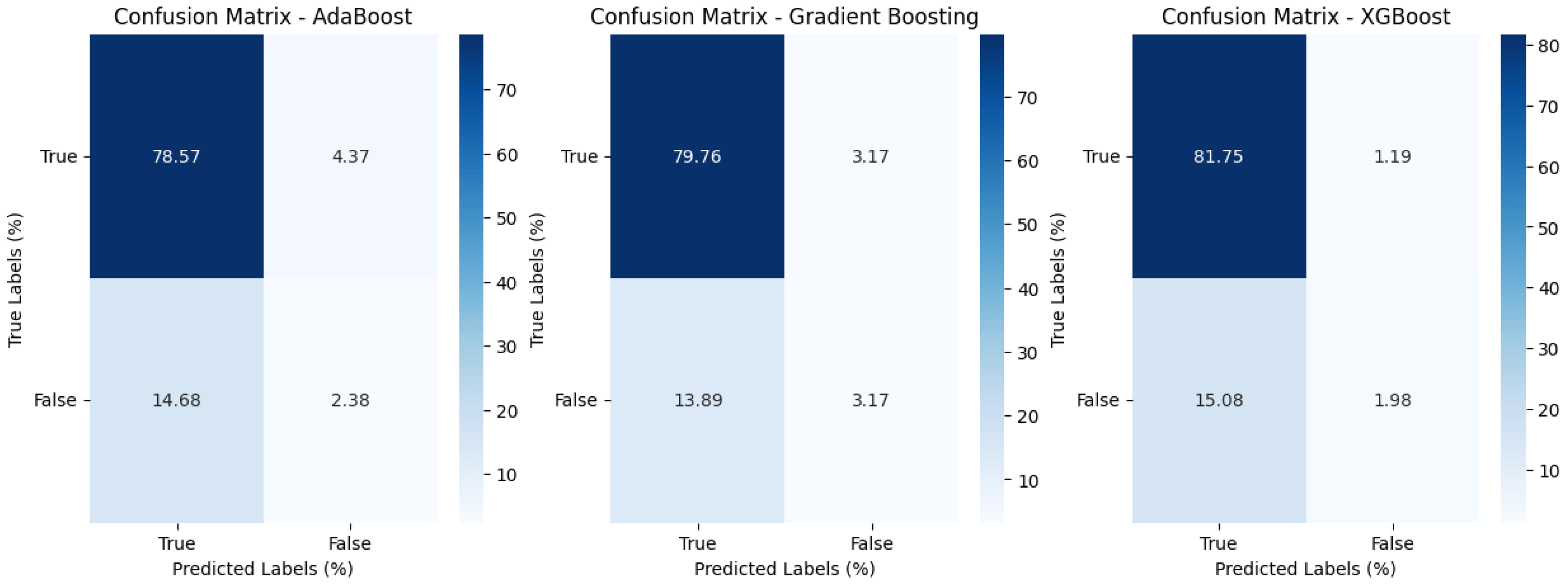
As seen in Figure 1, models tend to predict "easy" outcomes with high confidence, often missing out on more complex, harder-to-predict scenarios that may be crucial to understanding long-term trends. For example, in predicting default risk, easy predictions might include customers with poor credit scores and multiple late payments, but the harder cases—those who have recently recovered financially—may be overlooked, leading to misallocation of risk assessments.
In such cases, feature engineering—where a data scientist manually selects and refines the input variables—becomes pivotal. This process ensures that the model isn’t relying on misleading or superficial signals, further reducing the likelihood of bias.
Moral Responsibility and the Limits of De-Biasing
While automated de-biasing techniques exist, they do not eliminate the need for human oversight. In finance, the consequences of a biased model can be severe, whether it involves a trading algorithm unfairly excluding certain sectors or a credit risk model penalizing minority borrowers due to historical data imbalances. Thus, de-biasing techniques should be treated as tools rather than a final solution.
For instance, adjusting a credit risk model to remove bias against specific demographic groups might involve excluding features like zip code, which could indirectly encode racial or socioeconomic biases. But this alone doesn’t guarantee fairness. A vigilant data scientist must continuously monitor model performance and intervene where necessary, applying domain knowledge and judgment to ensure that the model remains both fair and effective.
Generalization Challenge of Making Robust Predictions in Finance
Generalization is the cornerstone of a successful machine learning model, especially in finance, where predictions are made on constantly evolving market conditions. A model's ability to generalize well means it can maintain predictive accuracy when exposed to new, unseen data. Ideally, a model’s performance is validated using a holdout set—data that was not part of the model's training process. However, even if the model performs well on this holdout set, it is not the final test of its robustness. The real test comes when the model is deployed in the real world, where data patterns change over time, and new economic conditions emerge.
In finance, this risk is compounded by a phenomenon known as concept drift. Concept drift occurs when the relationships between input features and the target variable evolve due to external factors, such as changes in economic policy, consumer behavior, or market volatility. This can significantly erode a model’s performance if not properly accounted for.
Credit Scoring Model Example
Consider the case of a credit-scoring company that develops a machine learning model to predict the likelihood of loan default. The model is trained on historical data from multiple lending institutions, and it performs exceptionally well on a holdout set, achieving high predictive accuracy. However, upon closer inspection, the team uncovers a puzzling variable: the customer’s account number. Strangely, the inclusion of this variable significantly improves the model’s predictive power.
At first, this seems counterintuitive. How could a customer’s account number—seemingly random—impact their likelihood of default? Upon further analysis, it becomes clear that the account number is indirectly correlated with the lending institution. Each institution assigns account numbers within a specific range, and these ranges correlate strongly with the type of clientele they serve. For instance, one institution may cater to low-risk, high-income clients, while another focuses on higher-risk, subprime borrowers.
Thus, the model is not predicting the creditworthiness of individuals but instead relying on hidden patterns within the data—specifically, the lending profile of each institution. This leads to a hidden bias in the model, which can skew predictions when applied across different lending institutions or in new economic contexts.
While the model may still work well for the institutions it was trained on, the reliance on account numbers means that its predictive power is institution-specific, limiting its generalizability. This raises a critical question: Is the model fit for wide-scale deployment, or does it need to be retrained on more generalized data that doesn’t carry institution-specific biases?
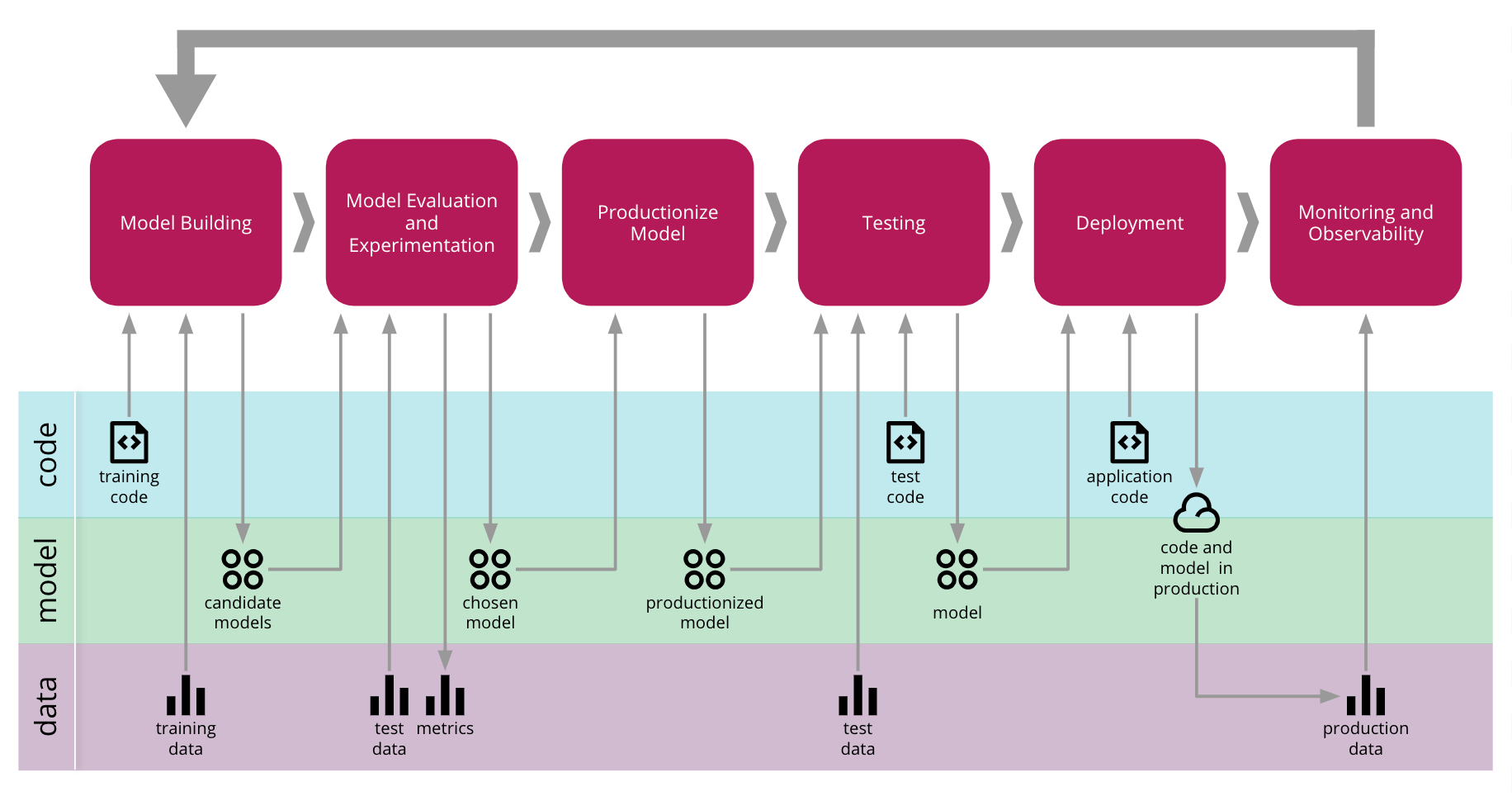
Solutions to Enhance Generalization
There are several methods to mitigate the risks associated with poor generalization and concept drift in financial models:
- Regular Model Updates: Continuously retrain models on the most recent data to capture the latest market trends.
- Cross-validation on Different Time Periods: Use time-based cross-validation to test how the model performs across different market cycles, such as bull and bear markets.
- Feature Selection: Manually review and adjust the features used in the model, removing those that may introduce institution-specific biases (e.g., account numbers).
- Ensemble Models: Combine multiple models trained on different periods or market conditions to improve robustness. For instance, an ensemble of models trained on pre-crisis and post-crisis data may generalize better than a single model trained on one period.
| Technique | Effectiveness |
|---|---|
| Regular Model Updates | High |
| Cross-validation | Medium |
| Feature Selection | Medium |
| Ensemble Models | High |
Continuous Improvement and Evolution of ML Models
Machine learning is not a "set-it-and-forget-it" solution, particularly in the fast-evolving world of finance. It is an iterative process, where models must be continuously refined and adapted as new data becomes available. Human intuition plays an essential role in this iterative process, helping to identify when a model requires adjustment or when an entirely new approach may be necessary.
For example, consider a quantitative trading algorithm designed to take advantage of arbitrage opportunities in currency markets. Initially, the model might perform well by exploiting inefficiencies in currency pricing across different exchanges. However, as more traders deploy similar algorithms, those inefficiencies disappear. A purely machine-driven approach may fail to recognize when its edge has eroded, leading to losses. Human intuition, however, can guide the adaptation of the model by recognizing this market shift and suggesting new strategies, such as leveraging alternative data or shifting focus to less crowded markets.
The Role of Human Adaptation to Change
In finance, market conditions are fluid and dynamic. Economic shifts, geopolitical events, and even technological innovations can lead to major disruptions. Machine learning models are built on historical data, but when the underlying economic environment changes, models may struggle to adapt. This is where human intuition becomes indispensable. A trained expert can detect early signs of change—whether it's increased volatility in emerging markets or shifts in consumer spending behavior—and guide the retraining or refinement of models.
For instance, during the 2008 financial crisis, many credit-risk models failed spectacularly because they were trained on pre-crisis data and could not account for the massive changes in consumer credit behavior. Experts who recognized these shifts were able to adjust their models by incorporating macroeconomic stress factors and deploying newer models that better handled high-risk environments.
Combining Human Intuition with Machine Learning
The increasing integration of AI and machine learning into the financial sector has demonstrated one crucial point: algorithms alone are not enough. While they are powerful tools, their success is inseparably linked to the human intuition that guides their development, evaluation, and ongoing adjustment. Whether it's addressing hidden biases, adapting to changing market dynamics, or continuously improving performance, human oversight is the key to ensuring that models remain effective and reliable.
As AI continues to advance and become an integral part of the finance workforce, it will, like previous technological innovations, separate the winners from the losers. Firms and professionals who embrace the complementary relationship between human insight and AI-driven models will excel. Those who fail to adapt may be left behind, as the financial landscape continues its rapid transformation.
In the end, the future of finance is not about choosing between humans and machines—it’s about leveraging both to their fullest potential.